
이전에 프로그램 회사를 다니면서 네이버 블로그에 정리해 놨던 문서들을 옮기기 시작했다.
하나하나 천천히 옮기려니 이거 생각보다 손이 많이 가는 작업이네....
'숨쉬기 활동' 카테고리의 다른 글
| 머리가 아프다 (0) | 2017.01.03 |
|---|---|
| 오늘도 소주 (0) | 2016.12.31 |
| 크리스마스땐 공부를 (0) | 2016.12.26 |
| 크리스마스와 함께하는 안드로이드 개발공부 (0) | 2016.12.25 |
| 판교에서 팀원들과 첫 점심 (0) | 2016.11.29 |

|
이전에 프로그램 회사를 다니면서 네이버 블로그에 정리해 놨던 문서들을 옮기기 시작했다.
하나하나 천천히 옮기려니 이거 생각보다 손이 많이 가는 작업이네....
| 머리가 아프다 (0) | 2017.01.03 |
|---|---|
| 오늘도 소주 (0) | 2016.12.31 |
| 크리스마스땐 공부를 (0) | 2016.12.26 |
| 크리스마스와 함께하는 안드로이드 개발공부 (0) | 2016.12.25 |
| 판교에서 팀원들과 첫 점심 (0) | 2016.11.29 |
이클립스의 단축키를 알아두면 개발시 유용한 것들이 많이 있다. 개발하면서 요정도 단축키를 상식적으로 알아두면 개발시간을 많이 단축시켜줄 것이다.
?1) 코딩을 할 때 라인 번호가 있으면 개발이 쉽다.
Window > Perferences > General > Editors > Text Editors > Show line numbers(항목의 체크박스에 체그하면된다)
2) 코드 스타일 바꾸기
Windows > Prefrences > Java > Code Style > Formatter
하나를 만들어서 그거 이용하도록
에디터에서 적용방법 : Ctrl + Shift + F 또는 Source > Format
특정부분만 적용하려면 블록 후 Ctrl + Shift + F
3) 퍼스펙티스 설정 저장
WIndow > Save Perspective As
4) 코드 어시스트 Ctrl + Space
for, while 자동완성
sysout 자동완성
템플릿 설정은 Preferences
Java > Editor > Templates
Actio 정도만 치고 Ctrl+Space를 치면 적당한 후보를 내준다.
for(int i = 0; i < array.length; i++)
이거 치기 귀찮다
for만 치시고 ctrl+space 누르시면
슈루룩 완성된다.
중간에 바꿔야 할건 tab키를 이용하면 바꿀 수 있다. 이건 습관되면 코딩 속도도 빨라지고 편해진다 ㅋ
5) Quick fix
에러난 줄에 노란전구가 있으면 Ctrl + 1 눌러서 방법중 하나 고르면 수정된다.
빨간 줄이 보이세요? 커서를 올려놓고 기다려보자.
올려놓고 기다리시면 왜 빨간줄이 나왔는지 나온다.
도대체 어떻게 고쳐야할지 모르겠다 싶으시면
한번 Ctrl+1을 눌러보면 알아서 고쳐줄지도 모른다.
6) Quick Type Hierarchy
메서드, 타입, 패키지를 선택하고 Ctrl + T
한번 더 누르면 뒤집어짐
7) Quick Outline
Ctrl + 0 키를 누르면 바로 필터링됨
8) 소스 코드 네비게이션
정의로 바로가기 : F3
다시 돌아오기 : Alt + <- , 다시 정의보기 : Alt + ->
Ctrl 누르고 있으면 각 요소가 하이퍼링크 모양으로 바뀜 : 이때 마우스 클릭시 이동
해당라인 이동 : Ctrl + L
9) Mark Occurences
툴바버튼이 눌려있으면 커서가 위치한 요소는 사용처가 다 보인다
10) getter, setter, 생성자
소스에서 Source > 해서 Generate getter and setter~ 선택해서 원하는 함수를 만들어준다.
11) 소스 비교
우클릭 > Compare with > Local History
Replace With > Local History
Restore from Local HIstory
12) 에디터간 이동
많아지면 오른쪽 >> 클릭
Ctrl + F6 :
13) 뷰 간 이동
Ctrl + F7
14) 퍼스펙티브간 이동
Ctrl + F8
15) 에디터로 돌아오기
어디에 있든지 F12 키 누르면 현 에디터로 돌아온다.
16) 찾기
점증적찾기 : Ctrl + J (아래에 Incremental File표시)
그리고 단어입력
그리고 Ctrl + J 클릭시 다음단어 찾음 (Ctrl + Shift + J는 반대)
블록선택후 Ctrl + K 클릭시 다음단어
검색기능
일반 검색 : Ctrl + F
마우스로 드레그한 항목 아래로 검색 : Ctrl + K
마우스로 드레그한 항목 위로 검색 : Ctrl + Shift + K
실시간 타이핑 검색 (아래로) : Ctrl + J
실시간 타이핑 검색 (위로) : Ctrl + Shift + J
17) 소스 편집
원하는 라인으로 이동 : Ctrl + L
한 라인 삭제 : Ctrl + D
주석처리 : Ctrl + Shift + / ---> 형태 : /* */
Ctrl + / ----> 형태 : //
자동 들여쓰기 정리 : Ctrl + I
자동으로 임포트하기 : Ctrl + Shift + O
소스창 전체화면 전환 : Ctrl + M
System.out.println(); 간단하게 입력하기 : sysout 입력 후 Ctrl + Space
try { } catch { } 간단하게 입력하기 : try 입력 후 Ctrl + Space
for문 간단하게 입력하기 : for 입력 후 Ctrl + Space
열린파일 이동할때 리스트 항목을 보고 선택하기 : Ctrl + F6
Ctrl + Shift + O - Organize Imports
저장전에는 필히 import 구문을 정리 해주시고..
Ctrl + Shift + F - Reformat source
저장전 소스 들여쓰기도 자동으로 정리해주시고
Alt + Shift + J - Java Doc Comment Create
아직도 Java Doc을 안다는가.. 달어줘라 개발자의 센스다. 일일히 타이핑 하는가..
이젠 이단축키 하나로.. 메소드나 클래스 명에 위치시키고 눌러봐라. 파라미터, throws를 분석하여 친절하게 Doc주석을 달어준다.
--------------------------------------------------------------------------------
1. 옮길 문장이 있는 줄을 아무데나 클릭한다.
2. Alt키와 화살표(위로)키를 누른다.
--------------------------------------------------------------------------------
18) 리펙토링
1. Source 메뉴에는 재미있는 기능이 많다.
- source =>Generate Getter and Setter를 보면
그동안 여러분을 괴롭혔던 mutator와 accessor를 편하게 구현하실 방법이 들어있다.
- source => Generate Constructors using Fields에서는
class variable만 선언하면 constructor가 자동으로 만들어지게 해준다.
ALT + SHIFT + Z = 블록설정 후 try-catch 문 덮어서 만들어주기
19) 디버깅
2. 버그가 있으십니까? 디버깅을 해보세요. (고급기능, 그러나 유용한 기능)
Ctrl+Shift+B를 누르면 breakpoint가 걸리고,
F11을 누르면 디버그 모드로 실행이 된다.
디버그 모드에서는 breakpoint의 위치에서 어떤 변수가 어떤 값을 가지는지 볼 수 있다.
한줄 한줄 실행해가며(보통 F6, 함수로 들어갈때 F5) 볼 수 있다.
아. 디버깅을 하시다보면 perspective(창의 배치)가 달라진다.
이때 디버깅을 마치고 돌아오시려면 오른쪽 위에 Debug / Java라고 쓰인 곳에 가셔서 Java를 선택하든 원하는 작업공간을 선택하면 도니다.
20) 주석 처리?
Ctrl + Shift + / - ins?tantly toggling comments
소스를 일일히 주석처리 하는가. 블로 주석이라면 마우스로 긁어서 한번에 주석처리 하자.
21) 기타
Alt +Shift + T - Show Refactor Quick Menu
팝업에 Refactor 선택에 명령어 수행 너무많은 시간이 소비된다. 한번에 단축키로 호출하자
22) 단축키호출
Ctrl + Shift + L - Hotkeys Table Call
이클립스의 핫키 목록을 볼수있는 핫키
Eclipse 단축키 확인 및 변경
Eclipse의 모든 단축키는 Window >> Preferences >> Workbench >> Keys 메뉴에서 확인 및 변경이 가능하다. 그 동안 다른 툴에서 자신의 손에 익숙한 단축키들이 있다면 이 메뉴에서 단축키들을 변경하는 것이 가능하다.
Java Editor 단축키
Ctrl + Shift + M : 캐럿이 위치한 대상에 필요한 특정 클래스 Import 시키기
Ctrl + Shift + O : 소스에 필요한 패키지를 자동으로 Import 시키기
Ctrl + Shift + F : 소스코드 자동 정리
Ctrl + Shift + G : 특정 메써드나 필드를 Reference하고 있는 곳을 찾는다.
Ctrl + Shift + K : 이전찾기 (또는, 찾고자하는 문자열을 블럭으로 설정한 후 역으로 찾고자 하는 문자열을 찾아감.)
Ctrl + shift + G : 특정 메써드나 필드를 참조하고 있는 곳을 찾는다.
Ctrl + shift + B : 현재커서위치에 Break point설정/해제
Ctrl + 1 : Quick Fix. 에러가 발생했을 경우 Quick Fix를 통해 쉽게 해결이 가능하다.(Rename에 주로 사용)
Ctrl + 2 + R : Rename (리팩토링)
Ctrl + Shift + / : 선택 영역 Block Comment 설정
Ctrl + Shift + : 선택 영역 Block Comment 제거
Ctrl + / : 한줄 또는 선택영역 주석처리 / 제거
Ctrl + S : 저장 및 컴파일
Ctrl + I : 소스 깔끔 정리(인덴트 중심의 자동구문정리)
Ctrl + space : 어휘의 자동완성(Content Assistance)
Ctrl + Q : 마지막 편집위치로 가기
Ctrl + L : 특정줄번호로 가기
Ctrl + D : 한줄삭제
Ctrl + O : Outline 창 열기
Ctrl + H : Find 및 Replace
Ctrl + K : 다음찾기(또는, 찾고자 하는 문자열을 블럭으로 설정한 후 키를 누른다.)
Ctrl + N : 새로운 파일 및 프로젝트 생성
Ctrl + Shift + S : 열려진 모든파일 저장 및 컴파일
Ctrl + 객체클릭(혹은 F3) : 클래스나 메소드 혹은 멤버를 정의한 곳으로 이동(Open Declaration)
Alt + Shift + UP : 커서를 기준으로 토큰단위 블럭지정 (괄호의 열고 닫기 쌍 확인에 유용) ==> 괄호의 뒤에 마우스 커서를 위치시킨 후 더블클릭한 것과 같은 효과
Alt + Shift + DOWN : 커서를 기준으로 토큰단위 블럭해제
Alt + Shift + J : 설정해 둔 기본주석을 자동으로 달기 (메소드나 멤버변수에 포커스 두고 실행)
Alt + / : Word Completion
Alt + Shift + R : Rename
Alt + ->, Alt + <- : 이후, 이전
해당 프로젝트에서 Alt + Enter : Project 속성
sysout > Ctrl + Space : System.out.println();
try > Ctrl + Space : 기본 try-catch문 완성
for > Ctrl + Space : 기본 for문 완성
템플릿을 수정,추가 : Preferences > java > editor > Templates
Ctrl + Alt + R
Ctrl + F11 : 실행
F11 : 디버깅 시작
F5 : step into
F6 : step over
F8 : 디버깅 계속
Ctrl + .
23) 에러위치로 이동
Ctrl + '.'
24) 키보드로 코드블럭 이동
Alt + 위 화살표 혹은 아래 화살표
25) 나의 포맷 적용
Ctrl + Shift + 'F'
단축키는 몰라도 상관이 없다. 단축키 모른다고 개발을 못하는 건 아니다. 하지만 자주 쓰면서
유요한 단축키들을 알아둔다면 개발을 좀더 편하게 빠르게 할 수 있을 것이다.
간단하게 정리하기 어려운 내용인것 같다. 토비의 스프링 프레임워크 책을 보아도 이해안가는 부분도 많다.
하지만 현재 전자정부 프레임워크를 쓰면서 기존의 내용을 알고 정리해 놓으면 좋을것 같아서 정리해 보려고 한다.
MVC 개념이란 무엇일까?
Spring이란 무엇일까? SPRING MVC란?
MVC 개념은 화면에서 보여주는 V(View), 데이터 처리관리는 M(Model)
V(View)와 M(Model) 를 연결시켜주는 C(Controller) 각 첫글자를 따서 MVC 라고 한다.
MVC개념은 User Interface 부분을 담당하는 부분과 실제 처리가 일어나는 부분을 최대한 서로 분리시켜 디자이너와 프로그래머 사이에 종속성을 최대한 줄이기 위한 방법론 중 하나이다. 또한 웹 개발을 하면서 클라이언트에서 요청시 처리 로직을
거쳐 데이타 처리를 하여 화면에 매핑시켜주는 일련의 반복적인 과정을 MVC 개념이라고 하겠다.
Spring은 간단히 스프링이라 지칭하지만 정확하게는 스프링 프레임워크 (Spring Framework) 라고 하는 것이 정확한 표현이다.
즉, 스프링은 자바 프레임 워크중 한 종류를 말한다. 프레임 워크에는 스트러츠, 스트러츠2, 스프링 등 여러 종류가 있는데, 처음
회사에 들어오기 전에는 스트러츠와 스트러츠2로 웹개발을 했던 기억이 있다. 회사에 들어와서는 스프링 2.5 부터시작해서 3.0
지금은 전자정부 프레임워크를 사용하기까지 다양한 자바 프레임워크를 경험해본 결과... 자바기반의 프레임 워크 중에는 스프링프레임워크가 가장 확장성이 좋고 사용하기 좋은 것 같다. 프레임워크의 버전이 올라갈 수록 개발자가 할 일과 신경쓸일이 줄어드는 것은 분명하다.(단, 잘 설계되어진 프레임워크를 사용한다는 가정) 많은 기능(보안,로그,라이브러리관리 등등) 들을 지원해 주기 때문에 공통/표준 설계자가 처음 프레임워크 설계만 잘해서 준다면 개발자들은 별 신경 없이 개발에만 집중할 수 있다. 토비의 스프링프레임워크 3.1에서는 자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경량급 애플리케이션 프레임워크라고 정의하고 있다. 프레임워크란 집을 짓는것을 예로 들면 말 그대로 집의 틀을 구성한다는 의미인데 그 틀을 어떻게 구성하느냐에 따라서 살만 붙히면 집이 완성되기 때문에 중요한 부분을 차지하는 것은 분명하다. 스프링 프레임워크를 정리하기엔 너무 많은 내용(POJO,AOP,DI,IoC 등등)들이 있으니 나중에 다시 보도록 하고, 본론으로 들어가 SPRING MVC 패턴이 무엇인지 정리해 보려 한다.
Spring MVC는 위에서 설명한 기본적인 요소 Model,View,Controller외에도 많은 컴포넌트들이 있다.
DispatcherServlet, HandlerMapping, Controller,Interceptor,Viewresolver,View 등 컴포넌트들이 존재하며
각 역활이 명확하게 분리되어 있다.
아래 설명은 각 컴포넌트들의 역활에 대한 설명이다.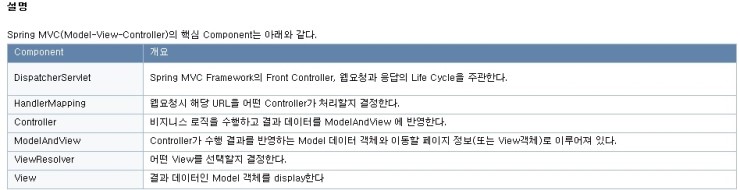
아래 그림은 스프링MVC 패턴의 흐름을 잘 설명해주는 그림으로 정말 여러번 보았지만 꾀 오랫동안 이해 가지 않았던 MVC흐름도이다. 지금 전체적인 그림은 아니지만 MVC 각 모듈이 어떤 일들을 하면서 진행되는지 알 수 있다.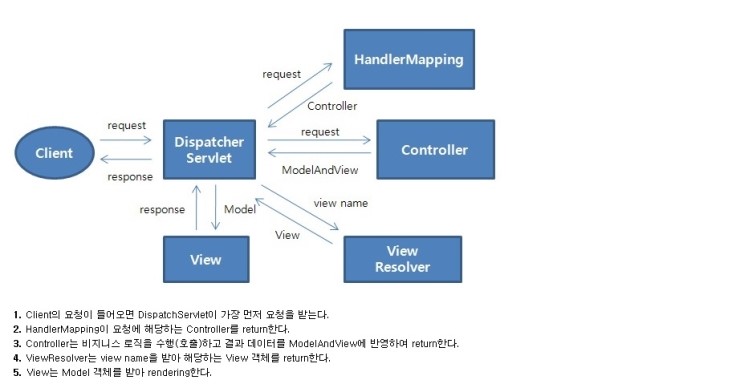
클라이언트가 요청을 하면 위 그림처럼 DispatcherServlet이 가장 먼저 요청을 받아 어느 Controller에서 일을 진행할지 정하기위해 HandlerMapping을 통해 리턴 받는다. Controller가 정해지면 해당 컨트롤러에서 인터페이스를 호출하고, 인터페이스 구현부를 호출하여 비즈니스 로직(Impl)을 수행하게 된다. 비즈니스 로직 단계에서 필요한 데이터들은 Dao를 호출하여
데이터 처리를 하며 DB에서 가져온 데이터를 Controller단계까지 가져와 화면과 매핑해주게 된다.
이때 데이터들을 담는 통?을 모델(model)이라고 하며 모델에 담겨온 정보들을 View Resolver에서 해당 화면과 매핑하는
작업을 하여 결과값을 리턴 해주고 마지막으로 데이터가 담겨있는 Model을 View로 던져주면 모든 클라이언트 Request 에 대한 Response 작업이 완료되어진다. 크게 클라이언트 요청이 시작되면 Presentation Layer => Business Layer => Data Layer 순으로 흘러가며 작업이 이루어 지는데 간단하게 정리해 보았다. 참고로 위의 그림은 Presentation Layer에서 클라이
언트 요청이 들어왔을때 이루어지는 흐름만 표현되어져 있다.
정리해 본다고 글을 적어보긴 했는데 정리하면서도 느끼는 것이지만 역시나 어렵다. 정리하자면 프레임워크에는 스트러츠, EJB,
스트러츠2, 스프링 등이 있고, 대부분 프로젝트에서 자바기반 프레임워크로는 가장 효츌적인 스프링프레임워크를 사용하고 있다.
물론 전자정부 프레임워크를 도입해 쓰기 시작했지만...
이 스프링프레임워크를 이해하기위해 Spring MVC 패턴에 대해 공부해 보았는데 더 깊은 이해를 위해서는 토비의 스프링프레임워크 3.5를 추천한다. 앞으로 클라우드 기술 표준을 잡기위해 공부해야할 부분이 많이 있는데~ 다음에 시간이 되면 스프링프레임워크가 무엇이며 전자정부 프레임워크가 왜 나오게 되었는지에 대해서 간단히 정리해 보도록 하겠다.
CONCAT 함수는 입력되는 두 문자열을 연결하여 반환한다.
문자열의 데이터타입은 CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB, NCLOB이며, 두 문자열 데이터 타입이 같으면, 그와 같은 데이터타입을 반환한다. 하지만 입력되는 두 문자열의 데이터타입이 다를 경우 NCLOB 데이터타입으로 반환된다.
【형식】
CONCAT( char1, char2 )
【예제】
SQL> select concat('My name is','홍길동') from dual;
-----------------------------------------------------------------
My name is 홍길동
단순히 문자열을 연결하여 반환하는 함수로? CONCAT는 오라클에서 자주 사용하는 익숙한 함수이다.
오늘 정리하고 싶은 WM_CONCAT 함수는 데이터가 그룹화 되어져 있을 때 여러행(Row)의 값을 하나의 컬럼으로 합쳐서
조회 할 수 있는 막강한 기능이라 정리해 보고자 한다.
예제) 아래 예제는 각 부서의 사람들의 이름을 한 ROW에 합쳐서 보여주고 싶을 때 ...
table name: dept_tb
dept_name || emp_name
=========================
인사과 영수
인사과 철수
인사과 민수
인사과 길동
=========================
SELECT wm_concat(emp_name)
FROM dept_tb
GROUP BY dept_name;
※ 단, 여기서 select 결과가 다음과 같이 'oracle.sql.CLOB@e62121' ? clob의 주소값을 반환하고 있는 경우가 있는데...
이때, TO_CHAR로 감싸서 반환해주면 해결된다! 혹시 그래도 해결이 안된다면... 전자정부프레엠워크 사용시 Oracle의 경우는 iBatis를 위한 sqlMapClient bean 설정 시 다음과 같이 lobHandler를 등록해 주어야 한다. (ex: context-sqlMap.xml) 보통은 공통 잡는 분들이 프레임워크 잡을떄 당연 추가하겠지만 혹시나..!!! <bean id="lobHandler" class="org.springframework.jdbc.support.lob.DefaultLobHandler" lazy-init="true" />
SELECT to_char(wm_concat(emp_name))
FROM dept_tb
GROUP BY dept_name;
[결과]
===============================
dept_name || emp_name
===============================
인사과 영수,철수,민수,길동
===============================
콤마 제거하고 조회 하고 싶을땐 (replace나 translate 함수) : 문자열을 치환해 주는 기능을 하는 표현식※ 단순 문자열 치환 : TRANSLATE('대상문자열', '비교문자', '바꿀문자')?SELECT translate(wm_concat(emp_name),'a,','a ')
FROM dept_tb
GROUP BY dept_name;
[결과]?==============================
dept_name || emp_name
==============================
인사과 영수철수민수길동
=============================
WM_CONCAT 함수에 대해 정리해 보았다. 알면 정말 유용한 오라클 함수들!! 모르면 정말 어떻게 해야할지
많은 고민들로 시간을 보내는 경우가 허다한데... 한 번 잘 정리해 놓고 이용하면 좋을 듯 싶다!
| TNS 리스너가 없습니다. (0) | 2016.12.16 |
|---|---|
| 오라클 sysdba접속 방법 (0) | 2016.12.16 |
| [오라클] TRIGGER 구문 정리 (0) | 2016.11.30 |
| [오라클] MERGE INTO 구문 정리 (0) | 2016.11.30 |
| [Oracle]오라클 잡 스케줄러 생성 (0) | 2016.11.30 |
오라클 JOB을 걸면 일정 주기마다 DML(INSERT,UPDATE,DELETE) 작업을 수행하게 하여 TABLE에 데이터 작업을 해줄 수 있다. 일정 주기나 시간이 아니라, TABLE에 어떤 이벤트가 발생했을 때 알아서 오라클에서 내가 정의 해놓은 작업들을 수행해 준다면 얼마나 좋을까? .... 바로 이때 사용 할 수있는 오라클 구문에는 트리거(TRIGGER)가 있다.
1. 트리거(TRIGGER) 정의
- 테이블에 어떤 이벤트가 발생했을 때, 자동으로 사용자가 정의한 PL/SQL 명령을 실행 할수 있는 구문이다.
2. 트리거(TRIGGER) 생성 구문
CREATE [OR REPLACE] TRIGGER 트리거명 [BEFORE | AFTER]
triggering-event[Insert,delete,update] ON 테이블명
[Referencing OLD AS {변경전 값을 참조하는 변수명} NEW AS {변경 후 값을 참조하는 변수명}]
[FOR EACH ROW]
[WHEN (condition)]?
DECLARE
--변수선언
BEGIN
--트리거 PL/SQL 명령 작성
EXCEPTION
END;
#구문에 대한 상세 설명#
- 행수준 트리거(Row -Level Triggers) : 트랜잭션내의 각 행에 대해 한 번만 수행(컬럼의 각각의 행의 데이터 행 변화가 생길 때마다
실행되며,각 데이터 해의 값을 제어할 수 있다.)
- 문장수준 트리거(Statement-level Triggers) : 트랜잭션내에서 한번만 수행되며, 컬럼의 각 데이터 행을 제어 할 수 없다.
※ 따라서, 위의 옵션을 어떻게 사용하느냐에 따라 만들수 있는 트리거 유형은
트리거 이벤트(INSERT,UPDATE,DELETE) 3종류, FOR EACH ROW 유무에 따른 2종류, Before와 After에 대해 2종류로
3*2*2 = 12가지 유형을 만들 수 있다.
3. 트리거(TRIGGER) 생성시 고려사항
1. 트리거는 각 테이블에 최대 3개까지 가능하다
2. 트리거 내에서는 COMMIT,ROLLBACK 문을 사용할 수 없다.
3. 이미 트리거가 정의된 작업에 대해 다른 트리거를 정의하면 기존의 것을 대체한다.
4. 뷰나 임시 테이블을 참조할 수 있으나 생성 할 수는 없다.
5. 트리거 동작은 이를 삭제하기 전까지 계속된다.
4. 트리거(TRIGGER) 활성 / 비활성화
ALTER TRIGGER [schema.]trigger DISABLE; ==> 비활성화
ALTER TRIGGER [schema.]trigger ENABLE; ==> 활성화
5. 트리거(TRIGGER) 상태 확인
select table_name, status from user_triggers; => 테이블 명과, 트리거 활성 상태를 확인 할 수 있다.
6. 트리거(TRIGGER) 삭제 구문
DROP TRIGGER [schema.]trigger
7. 트리거(TRIGGER) 작성 예문
예문 1) 테이블 변경 이력 관리를 위한 TRIGGER 구문
?CREATE OR REPLACE TRIGGER NAMDM.RECORD_CHANGE_LOG_TO_MDMTB090
AFTER DELETE OR INSERT OR UPDATE
OF VALUE
ON NAMDM.MDMTB010
REFERENCING NEW AS NEW OLD AS OLD
FOR EACH ROW
BEGIN
-- your code here
-- (Trigger template "Default" could not be loaded.)
IF :NEW.VALUE != :OLD.VALUE THEN -- 값이 변경된 경우만 저장!!!
INSERT INTO mdmtb090
(
SEQ, ITEM_ID, ATTR_ID, SCOPE,
OLD, NEW, BIGO, CHG_EMP, DAT
)
VALUES
(
MDM_TRIGGER_SEQ.NEXTVAL, NVL(:NEW.ITEM_ID,:OLD.ITEM_ID), NVL(:NEW.ATTR_ID,:OLD.ATTR_ID), NVL(:NEW.SCOPE,:OLD.SCOPE),
:OLD.VALUE, :NEW.VALUE, '', :NEW.CHG_EMP, SYSDATE
);
END IF;
END;
예문 2) 테이블에 이벤트 발생시 다른 테이블에 MERGE 하기 위한 TRIGGER 구문
CREATE OR REPLACE TRIGGER NATEST.CALL_ACT_CONFIRM
AFTER DELETE OR INSERT OR UPDATE
OF IF_FLAG
ON NATEST.TEST_IF
REFERENCING NEW AS NEW OLD AS OLD
FOR EACH ROW
BEGIN
IF :NEW.IF_FLAG = 'S' AND (:NEW.REVISION_ID <> '000' OR :NEW.REVISION_ID <> 'MRP' OR :NEW.REVISION_ID <> 'EXT') THEN
--SP_TESTTB020_PROCESS('ACT', 'CONFIRM',:NEW.M00001,:NEW.REVISION_ID,:NEW.M00069,:NEW.ASSINGEE_ID);
/* 4-2-1. TESTTB010로 데이터 복사 */
MERGE INTO TESTTB010 ORG
USING (
SELECT T1.ITEM_ID,
T1.ATTR_ID,
T1.SCOPE,
T1.VALUE WORK_VALUE,
T1.CHG_EMP,
T1.CHG_DATE
FROM TESTTB011 T1,
TESTTB020 T2
WHERE T1.ITEM_ID = T2.ITEM_ID
AND T1.REV_NO = T2.REV_NO
AND T2.STATUS = 'A'
AND T1.ITEM_ID = :NEW.M00001
AND T1.REV_NO = :NEW.REVISION_ID
AND T2.PLANT = :NEW.M00069
AND (T1.SCOPE = 'G' OR T1.SCOPE = 'C' OR T1.SCOPE = T2.REGION OR T1.SCOPE = T2.COMPANY OR T1.SCOPE = T2.PLANT)
) TMP
ON (
ORG.ITEM_ID = TMP.ITEM_ID
--AND ORG.REV_NO = TMP.REV_NO
AND ORG.ATTR_ID = TMP.ATTR_ID
AND ORG.SCOPE = TMP.SCOPE
) WHEN MATCHED THEN
UPDATE
SET ORG.VALUE = TMP.WORK_VALUE,
ORG.CHG_EMP = TMP.CHG_EMP,
ORG.CHG_DATE = TMP.CHG_DATE
WHEN NOT MATCHED THEN
INSERT
(
ORG.ITEM_ID, ORG.ATTR_ID, ORG.SCOPE, ORG.VALUE, ORG.CHG_EMP, ORG.CHG_DATE
) VALUES
(
TMP.ITEM_ID, TMP.ATTR_ID, TMP.SCOPE, TMP.WORK_VALUE, TMP.CHG_EMP, TMP.CHG_DATE
);
/* 4-2-2. ACT 데이터 'Y' */
MERGE INTO TESTTB020 ORG
USING (
SELECT TO_CHAR(SYSDATE,'YYYYMMDD') PROC_DATE,
ITEM_ID,
REV_NO,
'A' STATUS,
REGION,
MATR_TYPE,
FUNC_ROLE,
COMPANY,
PLANT,
'Y' CONFIRM,
:NEW.ASSINGEE_ID CHG_EMP
FROM TESTTB020
WHERE ITEM_ID = :NEW.M00001
AND REV_NO = :NEW.REVISION_ID
AND PLANT = :NEW.M00069
AND STATUS = 'C'
) TMP
ON (
ORG.ITEM_ID = TMP.ITEM_ID
AND ORG.REV_NO = TMP.REV_NO
AND ORG.STATUS = TMP.STATUS
AND ORG.REGION = TMP.REGION
AND ORG.MATR_TYPE = TMP.MATR_TYPE
AND ORG.COMPANY = TMP.COMPANY
AND ORG.PLANT = TMP.PLANT
) WHEN MATCHED THEN
UPDATE
SET ORG.CONFIRM = TMP.CONFIRM,
ORG.EMP_NO = TMP.CHG_EMP,
ORG.CHG_DATE = SYSDATE
WHEN NOT MATCHED THEN
INSERT
(
ORG.PROC_DATE, ORG.ITEM_ID, ORG.REV_NO, ORG.STATUS, ORG.REGION, ORG.MATR_TYPE, ORG.COMPANY, ORG.PLANT, ORG.CONFIRM, ORG.EMP_NO, ORG.CHG_DATE
) VALUES
(
TMP.PROC_DATE, TMP.ITEM_ID, TMP.REV_NO, TMP.STATUS, TMP.REGION, TMP.MATR_TYPE, TMP.COMPANY, TMP.PLANT, TMP.CONFIRM, TMP.CHG_EMP, SYSDATE
);
END IF;
IF :NEW.IF_FLAG = 'S' AND (:NEW.REVISION_ID = '000' OR :NEW.REVISION_ID = 'MRP' OR :NEW.REVISION_ID = 'EXT') THEN
MERGE INTO TESTTB010 ORG
USING (
SELECT T1.ITEM_ID,
T1.ATTR_ID,
T1.SCOPE,
T1.VALUE WORK_VALUE,
T1.CHG_EMP,
T1.CHG_DATE
FROM TESTTB011 T1,
MDTAT010 T4
WHERE T1.ITEM_ID = :NEW.M00001
AND T1.REV_NO = :NEW.REVISION_ID
AND T1.ATTR_ID = T4.ID
AND (T1.SCOPE = 'G' OR T1.SCOPE = 'C' OR T1.SCOPE = :NEW.REGION OR T1.SCOPE||'C' = (SELECT DISTINCT COMPANY FROM MDTCT050 WHERE PLANT = :NEW.M00069)||T4.CONTROL_LEVEL OR T1.SCOPE||'P' = :NEW.M00069||T4.CONTROL_LEVEL)
) TMP
ON (
ORG.ITEM_ID = TMP.ITEM_ID
--AND ORG.REV_NO = TMP.REV_NO
AND ORG.ATTR_ID = TMP.ATTR_ID
AND ORG.SCOPE = TMP.SCOPE
) WHEN MATCHED THEN
UPDATE
SET ORG.VALUE = TMP.WORK_VALUE,
ORG.CHG_EMP = TMP.CHG_EMP,
ORG.CHG_DATE = TMP.CHG_DATE
WHEN NOT MATCHED THEN
INSERT
(
ORG.ITEM_ID, ORG.ATTR_ID, ORG.SCOPE, ORG.VALUE, ORG.CHG_EMP, ORG.CHG_DATE
) VALUES
(
TMP.ITEM_ID, TMP.ATTR_ID, TMP.SCOPE, TMP.WORK_VALUE, TMP.CHG_EMP, TMP.CHG_DATE
);
END IF;
END;
| 오라클 sysdba접속 방법 (0) | 2016.12.16 |
|---|---|
| [오라클] WM_CONCAT 함수 사용하기 (0) | 2016.11.30 |
| [오라클] MERGE INTO 구문 정리 (0) | 2016.11.30 |
| [Oracle]오라클 잡 스케줄러 생성 (0) | 2016.11.30 |
| [인덱스] 오라클 인덱스는 언제 왜 생성할까? (0) | 2016.11.30 |
우선 MERGE 란 뜻은 무엇인가? 충돌나지 않게 합친다는 개념이다. SVN에서 MERGE는 소스들의 충돌을 방지하고 적절하게 누락되지 않게 통합하기 위해 사용한다. 오라클에서 MERGE 또한 같은 개념이다. TABLE에 존재하는 데이터는 그대로 변경만 하고 없는 데이터는 삽입을 하여 적절하게 통합하기 위한 예약어이다. 즉,
MERGE INTO 구문은 대상 테이블 해당 KEY에 맞는 데이터가 이미 존재하면 UPDATE!!,존재하지 않으면 INSERT를 하여 테이블 ROW가 충돌나지 않으며 데이터를 UPDATE,INSERT 등의 작업을 한번에 해줄 수 있다.
#오라클 MERGE INTO 문법#
MERGE INTO [1. 테이블 명 혹은 VIEW명] - Update또는 Insert할 테이블 명 혹은 뷰
USING [2. 조회서브쿼리] --(만약 INTO절의 동일 테이블이라면 dual 사용)
ON [1과2의 조인 조건] - 조인 조건의 KEY와 일치여부[UPDATE/INSERT 조건은 바로 ON절에 의해 결정]
WHEN MATCHED THEN -일치되는 경우 UPDATE
UPDATE SET -- ※조인조건(on)절에 사용한 컬럼은 UPDATE가 불가하다!!
[컬럼1] = [값1],
[컬럼2] = [값2]
...
WHEN NOT MATCHED THEN -일치 안 되는 경우 INSERT
INSERT(컬럼1, 컬럼2...)
VALUES(값1, 값2...)
※오라클 9i 버전 이상부터 사용이 가능하다.
※조건절에 사용한 컬럼은 UPDATE가 불가하다!!
그리고 놀라운 사실!! UPDATE 구문만 가능한게 아니라 상황에 따라서는 DELETE 구문도 가능하다! 잘 쓸 경우는 없지만. 존재하는 ROW는 삭제하고 존재하지 않는 ROW는 삽입해야하는 경우라든지 다양하게 응용 하여 한번에 삽입 삭제 변경 처리가 가능하다.
MERGE INTO [1. 테이블 명] - Update또는 Insert할 테이블 명
USING [2. 조회쿼리] --(만약 동일 테이블이라면 dual 사용)
ON [1과2의 조인 조건] -- 조인 조건의 KEY와 일치여부[UPDATE/INSERT 조건은 바로 ON절에 의해 결정]
WHEN MATCHED THEN -일치되는 경우 DELETE
DELETE [테이블 명] WHERE [컬럼1] = [값1] AND [컬럼2] = [값2]...
WHEN NOT MATCHED THEN -일치 안 되는 경우 INSERT
INSERT(컬럼1, 컬럼2...)
VALUES(값1, 값2...)
※오라클 10g 버전 부터 DELETE구문 가능하다.
위의 문법처럼 작성한 두가지 쿼리예이다.
-테이블의 비교 대상이 같은 경우 다음처럼 DUAL을 사용하면 된다.
MERGE INTO EXTTB020 ORG
USING (
SELECT TO_CHAR(SYSDATE,'YYYYMMDD') PROC_DATE,
p_item_id ITEM_ID,
p_rev_no REV_NO,
v_matr_type MATR_TYPE,
'0000' COMPANY,
'0000' PLANT,
p_chg_emp CHG_EMP
FROM DUAL -비교 대상이 같을 경우 DUAL 사용
) TMP
ON (
ORG.ITEM_ID = TMP.ITEM_ID
AND ORG.REV_NO = TMP.REV_NO
AND ORG.MATR_TYPE = TMP.MATR_TYPE
AND ORG.COMPANY = TMP.COMPANY
AND ORG.PLANT = TMP.PLANT
) WHEN MATCHED THEN
UPDATE
SET ORG.CONFIRM = TMP.CONFIRM,
ORG.EMP_NO = TMP.CHG_EMP,
ORG.CHG_DATE = SYSDATE
WHEN NOT MATCHED THEN
INSERT
(
ORG.PROC_DATE, ORG.ITEM_ID, ORG.REV_NO, ORG.MATR_TYPE, ORG.COMPANY,
ORG.PLANT, ORG.EMP_NO, ORG.CHG_DATE
) VALUES
(
TMP.PROC_DATE, TMP.ITEM_ID, TMP.REV_NO, TMP.MATR_TYPE, TMP.COMPANY,
TMP.PLANT, TMP.CHG_EMP, SYSDATE
);
MERGE INTO EXTTB011 ORG
USING (
SELECT T1.ITEM_ID,
T1.ATTR_ID,
T1.SCOPE,
T1.VALUE WORK_VALUE,
T1.CHG_EMP,
SYSDATE CHG_DATE
FROM EXTTB010 T1
WHERE T1.ITEM_ID = p_item_id
AND (T1.SCOPE) IN
(
SELECT v_region
FROM DUAL
UNION ALL
SELECT DISTINCT COMPANY
FROM EXTCT050
WHERE PLANT IN (
SELECT DISTINCT SCOPE FROM mdmtb011
WHERE item_id = p_item_id
AND attr_id = '69'
AND REV_NO = p_rev_no
AND TO_CHAR(CHG_DATE,'YYYYMMDDHHMM') IN (
SELECT MAX(TO_CHAR(CHG_DATE,'YYYYMMDDHHMM')) CHG_DATE FROM mdmtb011
WHERE item_id = p_item_id
AND attr_id = '69' /* PLANT */
AND REV_NO = p_rev_no
)
)
)
) TMP
ON (
ORG.ITEM_ID = TMP.ITEM_ID
AND ORG.REV_NO = 'EXT'
AND ORG.ATTR_ID = TMP.ATTR_ID
AND ORG.SCOPE = TMP.SCOPE
) WHEN MATCHED THEN
UPDATE
SET ORG.VALUE = TMP.WORK_VALUE,
ORG.CHG_EMP = TMP.CHG_EMP,
ORG.CHG_DATE = TMP.CHG_DATE
WHEN NOT MATCHED THEN
INSERT
(
ORG.ITEM_ID, ORG.REV_NO, ORG.ATTR_ID, ORG.SCOPE, ORG.VALUE, ORG.CHG_EMP, ORG.CHG_DATE
) VALUES
(
TMP.ITEM_ID, p_rev_no, TMP.ATTR_ID, TMP.SCOPE, TMP.WORK_VALUE, TMP.CHG_EMP, TMP.CHG_DATE
);
오라클에서 MERGE INTO 구문은 자주 사용하는 쿼리 구문이니 익혀두고 이용하면 좋을 듯 하다. 단, 9i 이상 오라클에서 사용 가능하다고 했지만 9i에서의 Merge 구문은 불완전 (DELETE구문도 10g 부터 사용가능 )하다. 또한 구문상 제약사항이 많기때문에 ON 구문에서 조건식을 잘못 넣으면 작동이 안된다; 10g 이상부터 구문을 자유롭게 이용할 수있다. 또한 Trigger 발생이 안된다는 것도 주의해야 하겠다. 그리고 당연한 애기겠지만 단순 INSERT 구문이나 UPDATE구문을 써도 문제가 안되는데 궂이 MERGE INTO를 남발? 하는것도 성능이 떨어지기 때문에(100~200만건 이상 TABLE에서는 느려지는듯 ㅜㅜ) 꼭 필요할 때 잘 쓰도록 하자^^
| [오라클] WM_CONCAT 함수 사용하기 (0) | 2016.11.30 |
|---|---|
| [오라클] TRIGGER 구문 정리 (0) | 2016.11.30 |
| [Oracle]오라클 잡 스케줄러 생성 (0) | 2016.11.30 |
| [인덱스] 오라클 인덱스는 언제 왜 생성할까? (0) | 2016.11.30 |
| 오라클 수동DB설치 정리 (0) | 2016.11.30 |
DBMS_JOB이란 오라클에서 주기적으로 수행되는 백업작업이나, 쿼리나 프로시져등의 JOB을 시간단위나 일 단위나 월 단위 등 주기적인 예약 작업으로 등록하여 동작할 수 있도록 하는 스케줄러이다.UNIX에서 CRONTAB을 돌리 듯이 DB에서 스케쥴러를 등록하여 일정 주기별로 원하는 작업을 할 수 있다는 점에서 유사한데 차이점은 CRON JOB은 OS가 직접 관리하고 실행하는 반면 DBMS_JOB에 등록된 JOB은 오라클이 관리한다.
[출처] [Oracle]오라클 잡 스케줄러 생성 - Job Scheduler (DBMS_JOB 패키지)|작성자 티시포스
위의 출처에 잘 정리되어져 있어서 블로그에 정리해 담아보았다.
* DBMS_JOB 패키지 내 프로시저 구성은 다음과 같다.
1. SUBMIT : DB에 새로운 JOB을 추가하는 프로시저
2. REMOVE : DB에 추가된 JOB을 삭제하는 프로시저
3. CHANGE : DB에 저장되어 있는 JOB의 field들을 변경하는 프로시저
4. WHAT : JOB이 수행하는 작업을 변경하는 프로시저
5. NEXT_DATE : JOB이 Schedule되어 Timer에 의해 자동으로 실행될 때를 변경하는 프로시저
6. INTERVAL : JOB 실행 주기 파라미터를 변경하는프로시저
7. BROKEN : DB에 저장되어 있는 JOB의 상태를 정상 or Broken 상태로 설정하는 프로시저
8. RUN : JOB을 현재 시점에서 즉시 수행시키는 프로시저
1. SUBMIT
DB에 새로운 JOB을 추가하는 프로시저
오라클 기본 셋팅 확인
|
SELECT * FROM V$PAPAMETER WHERE NAME LIKE '%job%'; |
여기에 'JOB_QUEUE_PROCESSES'의 값이 '0' 이면 스케줄러가 작동하지 않는다. (기본셋팅)
아래와 같이 변경
|
ALTER SYSTEM SET JOB_QUEUE_PROCESSES = 10; |
변경이 되었으면 JOB SCHEDULER를 생성한다.
DBMS_JOB 패키지 내 프로시저 이용
|
DECLARE X NUMBER; BEGIN SYS.DBMS_JOB.SUBMIT ( job => X ,what => '유저 명.저장프로시저 명;' ,next_date => to_date('10-03-2012 03:00:00','dd/mm/yyyy hh24:mi:ss') ,interval => 'TRUNC(SYSDATE+1)+3/24' ,no_parse => TRUE ); SYS.DBMS_OUTPUT.PUT_LINE('Job Number is : ' || to_char(x)); END; /
commit; ? |
* job : 실행할 job number
* what - 실행할 PL/SQL 프로시저(procedure) 명 혹은 psm 문장의 sequence
* next_date - job을 언제 처음 시작할 것인지 지정한다. date type으로 evaluate되는 문자열 입력(SYSDATE)
* interval - job을 수행한 후, 다음 실행시간까지의 시간을 지정한다. 위 셋팅은 매일 오전 3시 마다 실행한다.
* no_parse - true 이면 submit시에 job을 parsing하지 않는다.
마지막으로 로그(Job Number)를 찍어줌으로써 스케줄러가 정상적으로 돌아가는지 확인할 수 있다.
* job Interval 설정
SYSDATE+7 : 7일에 한번 씩 job 수행
SYSDATE+1/24 : 1시간에 한번 씩 job 수행
SYSDATE+30/ : 30초에 한번 씩 job 수행(24: 시간 당, 1440(24x60):분 당, 86400(24x60x60):초 당 )
TRUNC(SYSDATE, 'MI')+8/24 : 최초 job 수행시간이 12:29분 일 경우 매시 12:29분에 job 수행
TRUNC(SYSDATE+1) : 매일 밤 12시에 job 수행
TRUNC(SYSDATE+1)+3/24 : 매일 오전 3시 job 수행
NEXT_DAY(TRUNC(SYSDATE),'MONDAY')+15/25 : 매주 월요일 오후 3시 정각에 job 수행
TRUNC(LAST_DAY(SYSDATE))+1 : 매월 1일 밤 12시에 job 수행
TRUNC(LAST_DAY(SYSDATE))+1+8/24+30/1440 : 매월 1일 오전 8시 30분
* job queue 정보 VIEWING
SELECT * FROM DBA_JOBS
SELECT * FROM USER_JOBS
SELECT * FROM ALL_JOBS
2. REMOVE
DB에 추가된 job을 삭제하는 프로시저
|
DBMS_JOB.REMOVE(job); |
* job : 삭제할 job number
3. CHANGE
DB에 저장되어 있는 job의 field들을 변경하는 프로시저
|
DBMS_JOB.CHANGE(job, what, next_date, interval); |
* job : 실행할 job number
* what : 실행할 PL/SQL procedure 혹은 psm 문장의 sequence
* next_date : job을 다음 수행할 시간
* interval : job을 수행 후 nex_date를 update하기 위한 expression. date type으로 evaluate되는 문자열
4. WHAT
job이 수행하는 작업을 변경하는 프로시저
|
DBMS_JOB.WHAT(job, WHAT); |
* job : 실행할 job number
* what : 실행할 PL/SQL procedure 혹은 psm 문장의 sequence
5. NEXT_DATE
job이 schedule되어 Tibero에 의해 자동으로 실행될 때를 변경하는 프로시저
|
DBMS_JOB.NEXT_DATE(job, next_date); |
* job : 실행할 job number
* next_date : job이 schedule되어 실행될 시간
6. INTERVAL
job 실행주기 파라미터를 변경하는 프로시저
|
DBMS_JOB.INTERVAL(job, interval); |
* job : 실행할 job number
* interval : job을 수행 후 next_date를 update하기 위한 expression. date type으로 evaluate되는 문자열
7. BROKEN
DB에 저장되어 있는 job의 상태를 정상 or Broken 상태로 설정하는 프로시저
|
DBMS_JOB.BROKEN(job, broken, next_date); |
* job : 실행할 job number
* broken : job이 broken 된 경우 true, 정상 상태인 경우 false
8. RUN
job을 현재 session에서 즉시 수행시키는 프로시저.
job이 broken되어 있어도 실행하고, 실행에 성공한 경우 job을 정상 상태로 변경한다.
|
DBMS_JOB.RUN(job); |
* job : 실행할 job number
| [오라클] TRIGGER 구문 정리 (0) | 2016.11.30 |
|---|---|
| [오라클] MERGE INTO 구문 정리 (0) | 2016.11.30 |
| [인덱스] 오라클 인덱스는 언제 왜 생성할까? (0) | 2016.11.30 |
| 오라클 수동DB설치 정리 (0) | 2016.11.30 |
| WORKSHOP - TABLESPACE에 관하여... (0) | 2016.11.30 |
Index의 정의를 보면
1) 조회속도를 향상시키기 위한 데이터베이스 검색 기술
2)색인이라는 뜻으로 해당 테이블의 조회결과를 빠르게 하기 위해 사용.
즉 인덱스가 필요한 이유는 인덱스를 생성해 줌으로써 조회 속도를 빠르게 할 수 있다.
INDEX를 테이블의 특정 컬럼에 한개이상 주게 되면 INDEX TABLE이 따로 만들어 지고,
인텍스 컬럼의 로우값과 rowid 값이 저장되며 로우값은 정렬된 트리 구조로 저장시켜 두었다가
검색시 좀더 빠르게 해당 데이타를 찾는데 도움을 준다.
*테이블을 생성하고 컬럼을 만든 후 데이타를 삽입하면 하나의 ROW가 생성되며 이 ROW는 절대적인 주소를 가지게 되는데 이를 ROWID라고 한다.
하지만 DML 명령을 사용 할때는 원본 TABLE은 물론 INDEX TABLE에도 데이타를 갱신시켜 주어야 하기 때문에 UPDATE, INSERT, DELETE (DML) 명령을 쓸때 속도가 느려진다는 단점이 있다.
그렇기 때문에 무조건 인덱스를 생성한다고 좋은 것 많은 아니고 꼭 필요할 때만 분별하여 생성해 주어야 하는게 KEY POINT라 할 수 있겠다. 그럼 언제 인덱스(INDEX)를 생성해 주면 좋을까?
우선 데이터가 많이 쌓일거라고 예상되는 경우 혹은 많이 쌓여 있어 현재 화면에서 조회 속도가 너무 느릴때 인덱스 생성을 한다. 그리고 조회결과가 전체 데이터수의 3~5% 미만일 경우에는 인덱스 스캔이 효율적이고 적은 COST로 빠르게 데이터를 찾아낼 수 있다.(전체범위 3~5% 이상 되면 인덱스 스캔보다 풀스캔이 훨씬 유리)
쿼리 플랜을 떠보면 다음과 같은 단어로 확인 할 수 있다
인덱스 스캔 = Index Scan
풀 스캔 = Full Scan
반대로 INDEX생성이 불필요한 경우는?
1) 데이터가 적은(수천건 미만) 경우에는 인덱스를 설정하지 않는게 오히려 성능이 좋다.
2) 조회 보다 삽입, 수정, 삭제 처리가 많은 테이블
3) 조회결과가 전체행의 15% 이상 읽어들일 것으로 예상될때
INDEX 생성 문법은 간단하다
1) 단일 인덱스 지정
CREATE INDEX 인덱스 명 ON table_name (컬럼명)
2) 다중 인덱스(복합 인덱스) 지정
CREATE INDEX 인덱스 명 ON table_name (컬럼명1,컬럼명2,컬럼명3)
※ 복합 인덱스로 지정해준 테이블에서 복합 인덱스를 타게 하려면 복합 인덱스로 준 컬럼
을 조회쿼리에서 모두 조회조건에 사용해야 인덱스를 탈 확률이 높아진다.
예를 들면 다음과 같다
create index index_make1_dx on account(id);
create index index_make2_dx on account(name, date, dept_name);
※ 인덱스는 NOT NULL 값에 대해서만 생성되기 때문에 null 여부를 체크하는 비교문은 인덱스를 사용하지 못함.
INDEX 가능 컬럼
인덱스는 모든 컬럼에 적용가능하다.
그런데 오라클은 가공시킨 컬럼에도 적용가능하다. 아래 참고
CREATE INDEX IDX_NAME ON TABLE_NAME(ROUND(PRICE1-PRICE2));
ROUND(PRICE1-PRICE2) 는 컬럼은 아니지만 컬럼을 가공해서 만든 것이다.
이런 가공컬럼은 다음과 같은 SQL 쿼리로 인덱스를 탈수 있다.
SELECT * FROM TABLE_NAME WHERE ROUND(PRICE1-PRICE2) > 0
※ 인덱스 줄때의 가공컬럼과 같아야 한다.
SQL 쿼리의 INDEX SCAN 유무 체크 방법
1. 상용 DB 관리도구를 이용하는 방법
PL/SQL Developer, Toad 같은 도구에서 SQL문을 작성하고 실행하면 Explain plan 에서 확인 가능하다.
INDEX를 사용해야 할 컬럼?
1) where절이나 조인 조건에서 자주 사용되는 열에 생성
2) 열은 광범위한 값을 포함 할 때
3) 열은 많은수의 null값을 포함 할 때
4) 조회결과가 전체행의 2-4% 보다 적게 읽어들일 것으로 예상될 때
--테이블이 클때 적은 양의 로우를 검색할때 인덱스를 준다다. 적은 양을 검색하는데 테이블을 전체 풀스캔하면 시간이 오래 걸려서 꼭 index를 줘야 한다다.
INDEX를 사용하지 말아야할 컬럼?
1) 테이블에 데이타가 작은 경우
2) where절에 자주 사용되지 않는 열은 사용되지 않는다.
3) 조회결과가 전체행의 2-4% 이상을 읽어들일것으로 예상될때
4) 테이블이 자주 갱신될때
INDEX 생성시 고려사항해야 할 사항들은 무엇일까?
인덱스가 적용된 컬럼이 조건식에서 인덱스를 탈수있게 하려면 해당컬럼을 가공하지않거나 연산을 하지 않은 상태에서 비교해야 인덱스를 탄다.
예를들어 연락처컬럼의경우(010-1234-5678) 010 만 따로 문자열을 잘라(가공) 조건검색하면 인덱스를 타지 않는다.
왜냐하면 인덱스 컬럼에 변형이 일어나면 상대값과 비교되기 전에 먼저 가공이 된 후에 비교된다.하지만 인덱스는 가공되기 전의 값으로 생성되어 있기 때문에 당연히 인덱스를 사용할 수 없게 된다. 여기에서 외부적(External) 변형이란 사용자가 인덱스를 가진 컬럼을 어떤 SQL함수나 사용자 지정함수(User Defined Stored Function), 연산, 결합(||) 등으로 가공을 시킨 후에 발생되는 것이며 이러한 경우는 인덱스를 탈수 없어 변형이 일어나지 않도록 제대로 기술해야 한다.
그렇기 때문에 010과 1234과 5678를 각각의 컬럼으로 만들어 저장한 후 각각의 컬럼에 인덱스를 주면 아무런 가공없이 조건 검색이 가능하므로 인덱스를 탈수 있다.
테이블 컬럼에 인덱스가 있따면 테이블 컬럼을 변경하는것보다 비교값을 변경하여
비교해주는데 좋다. 왜냐면 그래야 인덱스를 타기 때문이다.
WHERE to_char(joindate, 'yyyymmdd') = '20150131'
WHERE joindate = TO_DATE('20150131','yyyymmdd')
인덱스를 타지 않는 CASE
SELECT * FROM ACCOUNT WHERE A_DAY+1>2;
SELECT * FROM ACCOUNT WHERE SUBSTR(A_STRDAY,1,1)='월';
SELECT * FROM EMP WHERE EMP_ID = NVL(EMP_ID,'10');
아래는 인덱스를 타는 CASE
SELECT * FROM ACCOUNT WHERE A_STRDAY='월요일';
SELECT * FROM ACCOUNT WHERE A_DAY>2;
SELECT * FROM EMP WHERE EMP_ID = NVL('10','20');
SELECT * FROM ACCOUNT WHERE A_STRDAY like '월요일%';
※ 첫번째 쿼리부터 인덱스효과가 크게 나타나는 순서
INDEX 타는 경우와 안타는 경우
안타는 경우
1. SELECT * FROM emp WHERE empno <> '1010035';
오라클에서 exists를 이용하여 타게 할수있다?
SELECT * FROM emp WHERE not exists
(select empno FROM emp WHERE empno = '1010035' and a.empno = b.empno);
INDEX 삭제 방법은 간단하다.
DROP INDEX INDEX_NAME;
※ TABLE이 삭제되면 INDEX도 삭제된다.
※ 인덱스의 소유자와 DROP ANY INDEX권한을 가진 사람만 인덱스 삭제가 가능합니다.
?이상으로 인덱스에 대한 정리를 마치고자 한다. 나는 위에 정리된 인덱스 개념처럼 조회되는 데이터 양은 3~5%밖에 안되며 엄청 느린.. 그리고 Explain plan 에서 확인 했을때 FULL SCAN을 타고 있는 상황에서 해당 컬럼에 INDEX를 생성해 주어 4분 이상 돌아가던 쿼리 속도를 4초 이내로 줄여 개선 할 수 있었다. 뿌듯한 성과였다. 이제 단순 개발 뿐만이 아니라 시스템의 성능과 품질을 고려할 수 있는 개발자가 되기위한 한걸음 도약이였다.
| [오라클] MERGE INTO 구문 정리 (0) | 2016.11.30 |
|---|---|
| [Oracle]오라클 잡 스케줄러 생성 (0) | 2016.11.30 |
| 오라클 수동DB설치 정리 (0) | 2016.11.30 |
| WORKSHOP - TABLESPACE에 관하여... (0) | 2016.11.30 |
| Administering User Security (0) | 2016.11.30 |
OCP라는 자격증을 취득 후 그다음 단계는 OCM이라는 자격증을 취득할 수 있다. 2010년도 그당시만 해도 OCM 자격증 취득자가 별로 없었다. 덤프를 외워서 취득할 수 있는 OCP와 달리 OCM은 실습도 있고 상당히 까다롭기 때문에 그만큼 자격증 취득 여부에 따라 회사에 들어갈때 그만큼 가산점을 얻을 수 있었다. OCM을 취득하기 위해 가장 첫번째 실습 시나리오가 바로 DB 수동 설치이다. 오늘은 DB 수동 설치 후 EM을 추가하는 것 까지 정리해 보고자 한다.
[CONTENTS]
1. 수동 DB 생성 (OCM 0 scenario)
2. DBMS_SPACE_ADMIN 을 이용한 Dictionary → Local migration
3. Enterprise Manager 추가
--수동 DB 설치 (SID-testdb)
1. Nomount 수행을 위한 구성
Parameter file (수동으로 생성해야 하므로 pfile 생성.)
$] cd $ORACLE_HOME/dbs
$] vi inittestdb.ora
-다음과 같이 파라메터 값을 입력한다.
#testdb.__db_cache_size=83886080
#testdb.__java_pool_size=4194304
#testdb.__large_pool_size=4194304
#testdb.__shared_pool_size=67108864
#testdb.__streams_pool_size=0
#*.background_dump_dest='/u01/app/oracle/admin/testdb/bdump'
#*.compatible='10.2.0.1.0'
#*.core_dump_dest='/u01/app/oracle/admin/testdb/cdump'
#*.db_domain=''
#*.db_recovery_file_dest='/u01/oradata/flash_recovery_area'
#*.db_recovery_file_dest_size=2147483648
#*.job_queue_processes=10
#*.nls_language='KOREAN'
#*.nls_territory='KOREA'
#*.open_cursors=300
#*.processes=150
#*.remote_login_passwordfile='EXCLUSIVE'
#*.user_dump_dest='/u01/app/oracle/admin/testdb/udump'
--필수 파라메터 값
*.db_name='testdb'
*.db_block_size=8192
*.db_file_multiblock_read_count=16
*.control_files='/u01/oradata/testdb/control01.ctl','/u01/oradata/testdb/control02.ctl'
*.pga_aggregate_target=16777216
*.sga_target=167772160
*.undo_management='AUTO'
*.undo_tablespace='UNDOTBS1'
> password file 생성
$ orapwd file = orapwtestdb password=oracle entries=5
>SID 변경
$ export ORACLE_SID=testdb
>필수 경로 사전 생성
ocp@orcl : /home/oracle> cd /u01/oradata/
ocp@orcl : /u01/oradata> mkdir testdb
ocp@orcl : /home/oracle> cd /u01/app/oracle/admin/
ocp@orcl : /u01/app/oracle/admin/> mkdir testdb
ocp@orcl : /u01/app/oracle/admin/> cd testdb
ocp@orcl /u01/app/oracle/admin/testdb> mkdir bdump udump cdump pfile adump
> $ sqlplus sys/oracle as sysdba
SQL> startup nomount
2. create database 구문 작성
$] vi credb.sql
다음과 같이 작성을 한다.
CREATE DATABASE testdb
LOGFILE
GROUP 1 ('/u01/oradata/testdb/redo01.dbf') SIZE 10M reuse,
GROUP 2 ('/u01/oradata/testdb/redo02.dbf') SIZE 10M reuse,
GROUP 3 ('/u01/oradata/testdb/redo03.dbf') SIZE 10M reuse
MAXLOGFILES 5
MAXLOGMEMBERS 5
MAXLOGHISTORY 1
MAXDATAFILES 100
MAXINSTANCES 1
DATAFILE '/u01/oradata/testdb/system01.dbf' SIZE 600M reuse
AUTOEXTEND on NEXT 10M MAXSIZE UNLIMITED
UNDO TABLESPACE undotbs1
DATAFILE '/u01/oradata/testdb/undotbs1.dbf' SIZE 100M reuse
AUTOEXTEND on NEXT 10M MAXSIZE 1000M
sysaux DATAFILE '/u01/oradata/testdb/sysaux01.dbf' SIZE 600M reuse
AUTOEXTEND on NEXT 10M MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE temp
TEMPFILE '/u01/oradata/testdb/temp01.dbf' SIZE 50M reuse
CHARACTER SET KO16MSWIN949
;
$ sqlplus sys/oracle as sysdba
SQL> @credb.sql -- 4분정도 소요
> database 상태 확인
SQL> select instance_name,status from v$instance;
> 유저 설정
SQL> alter user sys identified by oracle
SQL> alter user system identified by oracle
3. DATABASE INSTALL
$] vi dbinstall.sql
다음과 같이 입력한다
@@$ORACLE_HOME/rdbms/admin/catalog.sql
@@$ORACLE_HOME/rdbms/admin/catproc.sql
conn system/oracle
@@$ORACLE_HOME/sqlplus/admin/pupbld.sql
$] sqlplus sys/oracle as sysdba
SQL>@dbinstall.sql
--10분정도 소요됨
4. DBMS_SPACE_ADMIN을 이용한 Dictionary ->Local migration
SYS> select tablespace_name,extent_management form dba_tablespaces;
TABLESPACE_NAME EXTENT_MAN
------------------------------ ----------
SYSTEM DICTIONARY
UNDOTBS1 LOCAL
SYSAUX LOCAL
TEMP LOCAL
4 rows selected.
-- 현재 system tablespace가 dictionary 방식으로 되어 있는 걸 확인할 수 있고,
이것을 local 방식으로 이전수행 할 수 있다.
SYS> shutdown immediate
SYS> startup mount exclusive
SYS>alter database open;
-- 나머지 tablespace 중에 dictionary 방식의 tablespace가 있다면
해당 tablespace를 read only로 변경한다. (ex ? alter tablespace xxxx read only; )
SYS>alter tablespace sysaux offline;
--제한모드 설정
SYS>alter system enable restricted session;
SYS>select logins from v$instance;
LOGINS
----------
RESTRICTED
1 row selected.
--이전 수행
SYS>exec DBMS_SPACE_ADMIN.TABLESPACE_MIGRATE_TO_LOCAL('SYSTEM');
SYS> alter tablespace sysaux online;
SYS> alter system disable restricted session;
SYS> select tablespace_name,extent_management from dba_tablespaces;
TABLESPACE_NAME EXTENT_MAN
------------------------------ ----------
SYSTEM LOCAL
UNDOTBS1 LOCAL
SYSAUX LOCAL
TEMP LOCAL
4 rows selected.
5. EM (Enterprise Manager Database Control) 수동 구성
ocp@testdb : /home/oracle> export ORACLE_SID=testdb
ocp@testdb : /home/oracle> echo $ORACLE_SID
testdb
ocp@testdb : /home/oracle> cd $ORACLE_HOME
--testdb의 EM설치 여부 확인
ocp@testdb : /u01/app/oracle/product/10.2.0/db_1> ls
assistants has log opmn root.sh
bin hs md oracore root.sh.old
cdata install mesg oraInst.loc slax
cfgtoollogs install.platform mgw ord sqlj
clone inventory network oui sqlnet.log
config javavm nls owm sqlplus
crs jdbc oc4j perl srvm
css jdk ocp.mycorpdomain.com_orcl plsql startup.log
ctx jlib ocp.mycorpdomain.com_prod precomp sysman
dbs jre odbc racg uix
demo ldap olap rdbms wwg
diagnostics lib OPatch relnotes xdk
--현재 testdb는 EM이 없음을 알 수 있다.
--사전 암호 변경
ocp@testdb : /u01/app/oracle/product/10.2.0/db_1> emca -config dbcontrol db -repos create
ocp@testdb : /u01/app/oracle/product/10.2.0/db_1> ls
assistants hs mesg oraInst.loc sqlj
bin install mgw ord sqlnet.log
cdata install.platform network oui sqlplus
cfgtoollogs inventory nls owm srvm
clone javavm oc4j perl startup.log
config jdbc ocp.mycorpdomain.com_orcl plsql sysman
crs jdk ocp.mycorpdomain.com_prod precomp uix
css jlib ocp.mycorpdomain.com_testdb racg wwg
ctx jre odbc rdbms xdk
dbs ldap olap relnotes
demo lib OPatch root.sh
diagnostics log opmn root.sh.old
has md oracore slax
ocp.mycorpdomain.com_testdb확인!!
ocp@testdb : /u01/app/oracle/product/10.2.0/db_1/install> cat portlist.ini
iSQL*Plus HTTP port number =5560
Enterprise Manager Console HTTP Port (orcl) = 1158
Enterprise Manager Agent Port (orcl) = 3938
Enterprise Manager Console HTTP Port (prod) = 5500
Enterprise Manager Agent Port (prod) = 1830
Enterprise Manager Console HTTP Port (testdb) = 5501
Enterprise Manager Agent Port (testdb) = 1831
| [Oracle]오라클 잡 스케줄러 생성 (0) | 2016.11.30 |
|---|---|
| [인덱스] 오라클 인덱스는 언제 왜 생성할까? (0) | 2016.11.30 |
| WORKSHOP - TABLESPACE에 관하여... (0) | 2016.11.30 |
| Administering User Security (0) | 2016.11.30 |
| 마스터 TABLE 데이터 간단히 BACKUP 하기! (0) | 2016.11.30 |
오늘은 예전에 OCP 자격증을 취득하기위해 공부했던 내용 중 TABLESPACE에 관한 내용을 정리해보고자 한다. Tablespace 실습 및 내용을 정리하기 전에 간단히 테이블 스페이스 개념을 집고 넘어가려 한다. 테이블 스페이스는 테이블을 생성할 수 있는 물리적인 파일이다. 데이터베이스는 데이터를 테이블에 담는다. 그 테이블들은 어디에 담기게 되는것일까? 바로 물리적 파일인 테이블 스페이스에 담기게 되는 것이다. 데이터베이스를 만드는 것은 테이블스페이스를 만드는 것이라 보아도 되겠다.
Tablespace 실습 및 내용 정리.
[Tablespace Syntax]
CREATE[undo|tempoary|smallfile] TABLESPACE테이블스페이스 이름
DATAFILE[tempfile]'/경로/파일 이름1.dbf' SIZE integer [T/G/M/K] [reuse]
[autoextend on next n [M] maxsize n [[M]| unlimnited]
,'파일 이름2' SIZE integer [M/K]...
[ENCRYPTION USING '3DES168' DEFAULT STORAGE (ENCRYPTION) ->11gR1~
[MINIMUM EXTENT integer [M/K]]
[BLOCK integer [k]]
[DEFAULT STORAGE(
INITIAL integer [M/K]
NEXT integer [M/K]
MAXEXTENTS integer
PCTINCREASE integer)]
[ONLINE|OFFLINE]
[LOGGING|NOLOGGING]
[PERMANENT|TEMPORARY]
[EXTENT MANAGEMENT
DICTIONARY|LOCAL
AUTOALLOCATE|UNIFORM SIZE integer [M/K]]
[SEGMENT SPACE MANAGEMENT (MANUAL/AUTO)]
- 테이블스페이스 생성하기
SYS> create tablespace sales_tbs
2 datafile '/u01/oradata/orcl/sales_tbs01.dbf' size 10m
3 autoextend on next 1m maxsize 100m
4 online logging
5 extent management local uniform size 128k
6 segment space management auto;
Tablespace created.
- sales_tbs 테이블 스페이스에 table생성
SYS> create table hr.sales00
2 (order# number(10) primary key, order_date date default sysdate)
3 tablespace sales_tbs;
Table created.
- 데이터 입력
SYS> begin
2 for i in 1..1000 loop
3 insert into hr.sales00 (order#) values (i);
4 end loop;
5 commit;
6 end;
7 /
PL/SQL procedure successfully completed.
-- EM을 통해 Sales_tbs의 tablespace용량이 늘어나는 것을 확인할 수 있다.
SYS> ed
Wrote file afiedt.buf
1 begin
2 for i in 1001..10000 loop
3 insert into hr.sales00 (order#) values (i);
4 end loop;
5 commit;
6* end;
SYS> /
PL/SQL procedure successfully completed.
--Viewing Tablespace Information(사용현황조회)
SYS> select * from DBA_TABLESPACE_USAGE_METRICS;
TABLESPACE_NAME USED_SPACE TABLESPACE_SIZE USED_PERCENT
------------------------------ ---------- --------------- ------------
EXAMPLE 8952 4194302 .213432414
SALES_TBS 64 12800 .5
SYSAUX 32632 4194302 .778007878
SYSTEM 60976 4194302 1.45378182
TEMP 0 4194302 0
UNDOTBS1 296 4194302 .007057193
USERS 840 4194302 .02002717
7 rows selected.
SYS>select tablespace_name from DBA_TABLESPACES;
TABLESPACE_NAME
------------------------------
SYSTEM
UNDOTBS1
SYSAUX
TEMP
USERS
EXAMPLE
INVENTORY
RMAN_TBS
UTEST02
UTEST03
UTEST04
TABLESPACE_NAME
------------------------------
UTEST05
12 rows selected.
-- tablespace 공간 변경 3가지 방법
SYS> --1. add datafile
SYS> alter tablespace inventory
2 add datafile '/u01/oradata/orcl/inventory02.dbf' size 10m;
Tablespace altered.
SYS> --2. resize
SYS> alter database datafile '/u01/oradata/orcl/inventory02.dbf' resize 20m;
Database altered.
SYS> --3. autoextend
SYS> alter database datafile '/u01/oradata/orcl/inventory02.dbf'
2 autoextend on next 1m maxsize 50m;
Database altered.
--tablespace 이동(datafile)
1. System TBS (offline 설정 안됨)
1) shutdown immediate
2) cp를 통해 복사(이동) - 물리적
3) startup mount
4) alter database rename file '원래' to '새로운'; - 논리적
5) alter database open;
6) 이전 file 삭제
2. Non-System TBS
1) 해당 TBS. offline 설정
2) cp를 통해 복사(이동) - 물리적
3) alter tablespace XXXX rename datafile '원래' to '새로운' ; - 논리적
4) 해당 TBS online설정
5) 이전 file삭제
-- tablespace삭제하기
1. TBS가 비어있는 경우
SQL> drop tablespace XXXXX;
2. TBS에 Object가 존재하는 경우 포함 삭제
SQL> drop tablespace XXXX including contents;
3. OSfile 동반삭제
SQL> drop tablespace XXXX including contents and datafiles;
4. 다른 TBS의 Object와 참조무결성 제약조건에 연결되어 있는 경우.
SQL> drop tablespace XXXX including contents and datafiles cascade constraints;
--close backup
ocp@orcl : /home/oracle> ls
20100823-3.sql Desktop insert.sql lob_04_04.sql sqlnet.log
afiedt.buf dict.sql inst.sql lock_trace.sql test1.sql
backup emp10000.sql jazn.sh lock_trace_user.sql v_scan.sql
const.sql hidden.sql lab_01_07.sql orcl_start.sh xbh.sql
creuser.sql holding.sql labs practice01_02.sql
ocp@orcl : /home/oracle> cd backup
ocp@orcl : /home/oracle/backup> ls
pfile_backup
ocp@orcl : /home/oracle/backup> mkdir close open rman rman_con archive
ocp@orcl : /home/oracle/backup> ls
archive close open pfile_backup rman rman_con
ocp@orcl : /home/oracle/backup> cd close/
ocp@orcl : /home/oracle/backup/close> cp /u01/oradata/orcl/* ./
cp: omitting directory `/u01/oradata/orcl/arch1'
ocp@orcl : /home/oracle/backup/close>
################################
############실습################
################################
1. WS1 Tablespace 생성 관리 실습
########################################
#####실습 1 데이터베이스의 저장구조##########
########################################
SYS>!t_scan.sql
/bin/bash: t_scan.sql: command not found
--자주 사용함으로 스크립트 생성
SYS>!vi t_scan.sql
SYS>!cat t_scan.sql
col tablespace_name format a15;
col file_name format a45;
select tablespace_name,status,contents,
extent_management,segment_space_management
from dba_tablespaces;
SYS>@t_scan
TABLESPACE_NAME STATUS CONTENTS EXTENT_MAN SEGMEN
--------------- --------- --------- ---------- ------
SYSTEM onLINE PERMANENT LOCAL MANUAL
UNDOTBS1 onLINE UNDO LOCAL MANUAL
SYSAUX onLINE PERMANENT LOCAL AUTO
TEMP onLINE TEMPORARY LOCAL MANUAL
USERS onLINE PERMANENT LOCAL AUTO
EXAMPLE onLINE PERMANENT LOCAL AUTO
INVENTORY onLINE PERMANENT LOCAL AUTO
INSA onLINE PERMANENT LOCAL AUTO
RMAN_TBS onLINE PERMANENT LOCAL AUTO
9 rows selected.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /u01/oradata/orcl/insa03.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
INSA 2097152 /home/oracle/backup/insa02.dbf
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
10 rows selected.
SYS>select tablespace_name,bytes,file_name from dba_temp_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
TEMP 41943040 /u01/oradata/orcl/temp01.dbf
########################################
실습 2 사용자용 테이블스페이스 생성#####
########################################
SYS>drop tablespace insa including contents and datafiles cascade constraints;
Tablespace dropped.
SYS>create tablespace insa
2 datafile '/u01/oradata/orcl/insa01.dbf' size 1M
3 segment space management auto;
Tablespace created.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 1048576 /u01/oradata/orcl/insa01.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
8 rows selected.
SYS>@t_scan.sql
TABLESPACE_NAME STATUS CONTENTS EXTENT_MAN SEGMEN
--------------- --------- --------- ---------- ------
SYSTEM onLINE PERMANENT LOCAL MANUAL
UNDOTBS1 onLINE UNDO LOCAL MANUAL
SYSAUX onLINE PERMANENT LOCAL AUTO
TEMP onLINE TEMPORARY LOCAL MANUAL
USERS onLINE PERMANENT LOCAL AUTO
EXAMPLE onLINE PERMANENT LOCAL AUTO
INVENTORY onLINE PERMANENT LOCAL AUTO
INSA onLINE PERMANENT LOCAL AUTO
RMAN_TBS onLINE PERMANENT LOCAL AUTO
9 rows selected.
##########################################
실습 3 : 사용자용 테이블스페이스 확장#####
##########################################
SYS>alter database datafile
2 '/u01/oradata/orcl/insa01.dbf' resize 2M;
Database altered.
SYS>select tablespace_name, bytes/1024/1024,
2 file_name from dba_data_files;
TABLESPACE_NAME BYTES/1024/1024 FILE_NAME
--------------- --------------- ---------------------------------------------
USERS 6.25 /u01/oradata/orcl/users01.dbf
SYSAUX 260 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 35 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 490 /u01/oradata/orcl/system01.dbf
EXAMPLE 100 /u01/oradata/orcl/example01.dbf
INSA 2 /u01/oradata/orcl/insa01.dbf
INVENTORY 100 /u01/oradata/orcl/inventory
RMAN_TBS 100 /u01/oradata/orcl/rman01.dbf
8 rows selected.
SYS>alter tablespace insa
2 add datafile '/u01/oradata/orcl/insa02.dbf' size 2M;
Tablespace altered.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /u01/oradata/orcl/insa02.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
9 rows selected.
SYS>alter tablespace insa add datafile
2 '/u01/oradata/orcl/insa03.dbf' size 2M
3 Autoextend on Next 1M Maxsize 10M;
Tablespace altered.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /u01/oradata/orcl/insa02.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
INSA 2097152 /u01/oradata/orcl/insa03.dbf
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
10 rows selected.
##########################################
실습 4 : 사용자용(일반) 데이터 파일 이동##
##########################################
SYS>alter tablespace insa offline;
Tablespace altered.
SYS>!cp /u01/oradata/orcl/insa02.dbf /home/oracle/backup/
SYS>alter tablespace insa rename
2 datafile '/u01/oradata/orcl/insa02.dbf'
3 to '/home/oracle/backup/insa02.dbf';
Tablespace altered.
SYS>alter tablespace insa online;
Tablespace altered.
SYS>!rm /u01/oradata/orcl/insa02.dbf
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /home/oracle/backup/insa02.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
INSA 2097152 /u01/oradata/orcl/insa03.dbf
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
10 rows selected.
#################################################
실습 5 : System 테이블스페이스 데이터 파일 이동##
#################################################
SYS>shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SYS>!cp /u01/oradata/orcl/system01.dbf /home/oracle/backup/system01.dbf
SYS>startup mount;
ORACLE instance started.
Total System Global Area 167772160 bytes
Fixed Size 1218292 bytes
Variable Size 83888396 bytes
Database Buffers 75497472 bytes
Redo Buffers 7168000 bytes
Database mounted.
SYS>alter database rename
2 file '/u01/oradata/orcl/system01.dbf'
3 to '/home/oracle/backup/system01.dbf';
Database altered.
SYS>!rm /u01/oradata/orcl/system01.dbf
SYS>alter database open;
Database altered.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /home/oracle/backup/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /home/oracle/backup/insa02.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
INSA 2097152 /u01/oradata/orcl/insa03.dbf
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
10 rows selected.
==> System Tablespace를 다시 원래 경로로 바꾸기!
SYS>shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SYS>!cp /home/oracle/backup/system01.dbf /u01/oradata/orcl/system01.dbf
SYS>startup mount;
ORACLE instance started.
Total System Global Area 167772160 bytes
Fixed Size 1218292 bytes
Variable Size 83888396 bytes
Database Buffers 75497472 bytes
Redo Buffers 7168000 bytes
Database mounted.
SYS>alter database rename
2 file '/home/oracle/backup/system01.dbf'
3 to '/u01/oradata/orcl/system01.dbf';
Database altered.
SYS>!rm /home/oracle/backup/system01.dbf
SYS>alter database open;
Database altered.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INSA 2097152 /u01/oradata/orcl/insa01.dbf
INSA 2097152 /home/oracle/backup/insa02.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
INSA 2097152 /u01/oradata/orcl/insa03.dbf
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
10 rows selected.
#################################################
실습 6. 테이블 스페이스의 삭제###################
#################################################
SYS>drop tablespace insa
2 including contents and datafiles cascade constraints;
Tablespace dropped.
SYS>select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
USERS 6553600 /u01/oradata/orcl/users01.dbf
SYSAUX 272629760 /u01/oradata/orcl/sysaux01.dbf
UNDOTBS1 36700160 /u01/oradata/orcl/undotbs01.dbf
SYSTEM 513802240 /u01/oradata/orcl/system01.dbf
EXAMPLE 104857600 /u01/oradata/orcl/example01.dbf
INVENTORY 104857600 /u01/oradata/orcl/inventory
RMAN_TBS 104857600 /u01/oradata/orcl/rman01.dbf
7 rows selected.
2. 1552 WS1-1-ch05. Creation Tablespace LAB (OCM-1)
문제1. dictionary를 생성할 수 없음 local로 생성 가능.
문제2.
SYS>create tablespace utest02
2 datafile '/home/oracle/backup/tstest/utest02.dbf' size 1m reuse
3 autoextend on next 1m maxsize 10m
4 extent management local uniform size 100k;
Tablespace created.
문제3.
SYS>create tablespace utest03
2 datafile '/home/oracle/backup/tstest/utest03.dbf' size 1m reuse
3 extent management local uniform size 100k;
Tablespace created.
문제4.
SYS>create tablespace utest04
2 datafile '/home/oracle/backup/tstest/utest04.dbf' size 2m reuse
3 extent management local autoallocate
4 segment space management auto;
Tablespace created.
문제5.
SYS>create temporary tablespace utest05
2 tempfile '/home/oracle/backup/tstest/utest05.dbf' size 10m reuse
3 extent management local uniform size 1m;
Tablespace created.
--tablespace 생성 확인
SYS>exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, OLAP and Data Mining options
ocp@orcl : /home/oracle> cd backup/tstest
ocp@orcl : /home/oracle/backup/tstest> ls
utest02.dbf utest03.dbf utest04.dbf utest05.dbf
| [인덱스] 오라클 인덱스는 언제 왜 생성할까? (0) | 2016.11.30 |
|---|---|
| 오라클 수동DB설치 정리 (0) | 2016.11.30 |
| Administering User Security (0) | 2016.11.30 |
| 마스터 TABLE 데이터 간단히 BACKUP 하기! (0) | 2016.11.30 |
| Linux 기반의 Oracle10g 설치 (0) | 2016.11.30 |