

오라클 12c 설치
윈도우10에 오라클 12c를 설치
오라클사이트
winx64_12102_database_1of2
winx64_12102_database_2of2
Windows10환경에서 오라클12c를 설치를 해보았다.
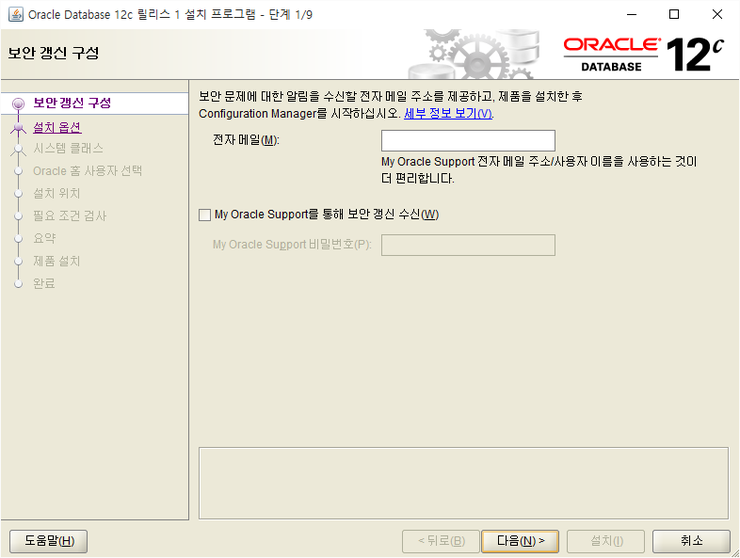
전자메일 무시하고 다음으로 넘기자

메일제공하기싫으면 무시하고 다음 예
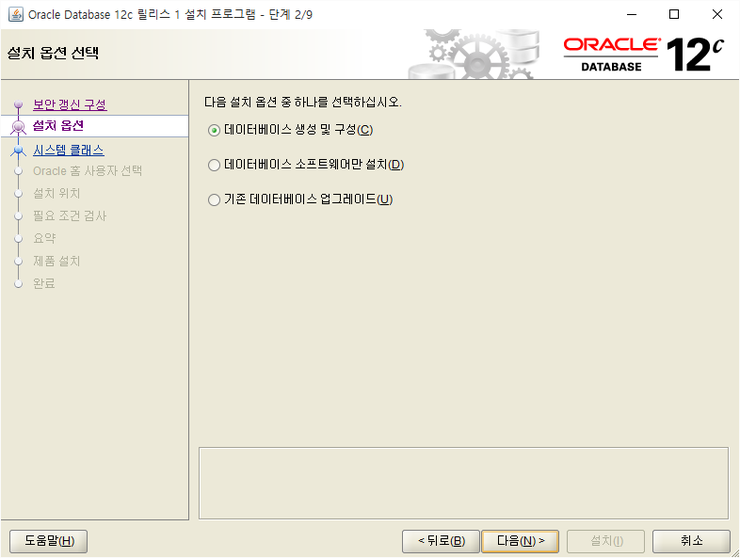
데이터베이스 생성 및 구성
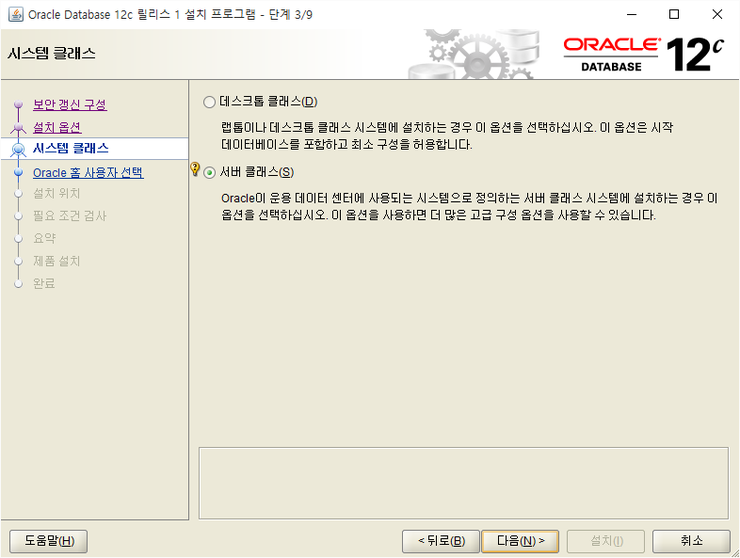
서버클래스
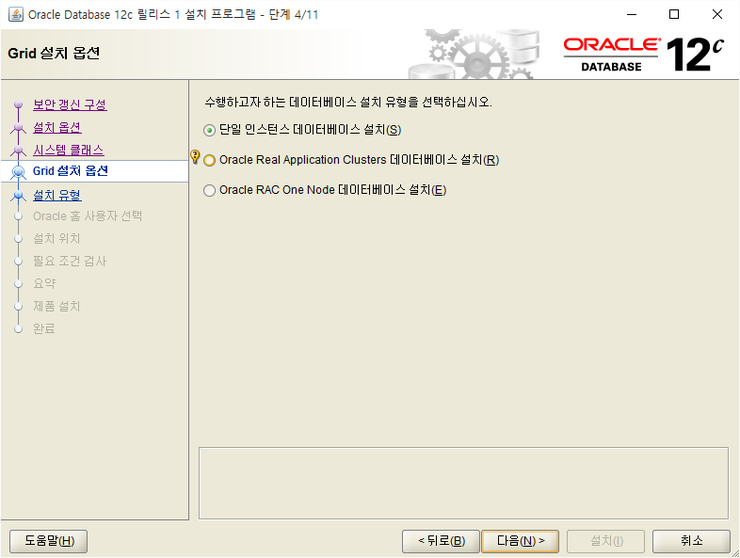
단일 인스턴스 데이터베이스 설치
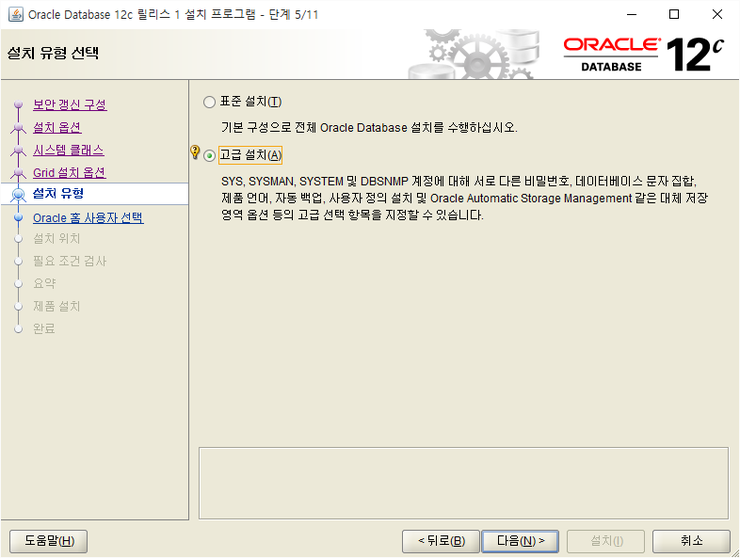
고급설치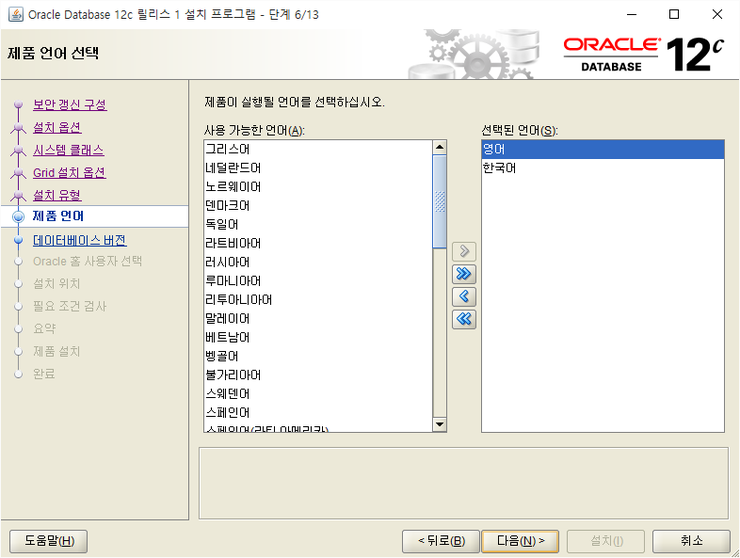
영어/한국어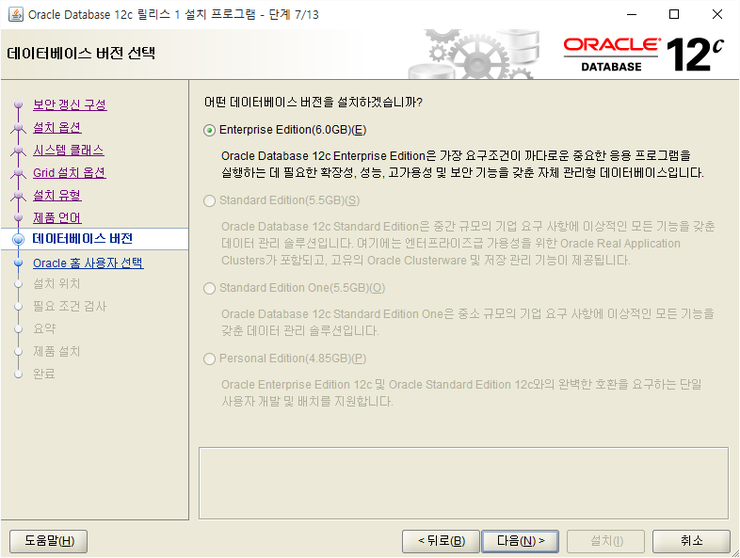
엔터프라이즈 에디션
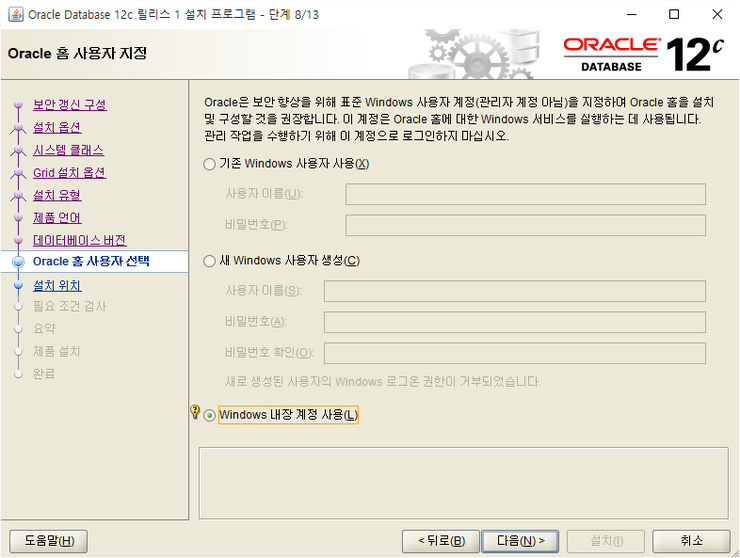
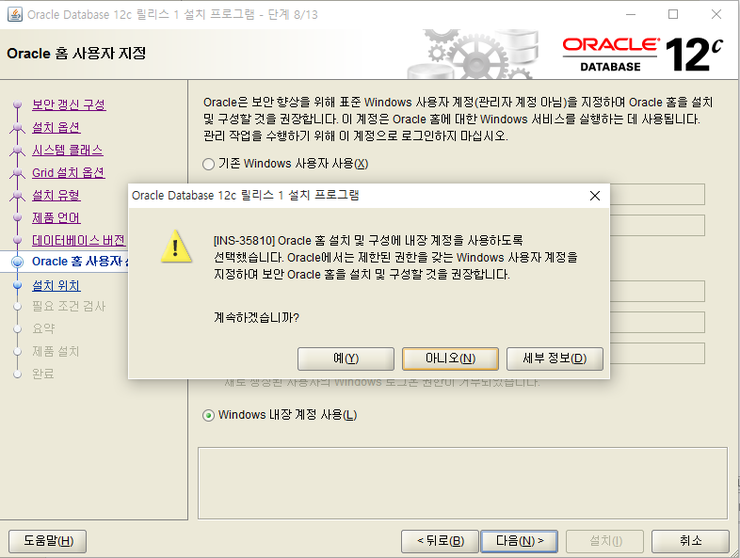
Oracle 홈 사용자 지정(Microsoft Windows 운영 체제 전용)
Windows 내장 계정을 사용하거나 표준 Windows 사용자 계정(관리자 계정 아님)을 지정하여 Oracle 홈을 설치하고 구성하십시오. 이 계정은 Oracle 홈에 대한 Windows 서비스를 실행하는 데 사용됩니다. 관리 작업을 수행하기 위해 이 계정으로 로그인하지 마십시오.
기존 Windows 사용자 사용
계정은 Windows 로컬 사용자, Windows 도메인 사용자 또는 Windows MSA(관리 서비스 계정)일 수 있습니다. Windows 로컬 또는 도메인 사용자에 대해 사용자 이름과 비밀번호를 제공해야 합니다. 관리 도메인 계정인 MSA 계정의 경우 사용자 이름만 제공하면 됩니다.
Oracle RAC Database 및 Oracle Grid Infrastructure 설치의 경우 Windows 도메인 사용자 계정만 사용할 수 있습니다.
새 Windows 사용자 생성
Oracle Universal Installer를 사용하여 생성할 Windows 로컬 사용자의 사용자 이름과 비밀번호를 제공합니다. 비밀번호를 확인합니다. 새로 생성된 사용자는 Windows 컴퓨터에 대화식 로그온 권한이 거부되어 있습니다. 그러나 Windows 관리자가 다른 Windows 계정과 마찬가지로 이 계정을 관리할 수 있습니다.
Windows 내장 계정 사용
사용자 이름이나 비밀번호가 필요하지 않습니다. Oracle은 Windows 내장 계정(LocalSystem 또는 LocalService)을 사용하여 Windows 서비스를 생성합니다.
데이터베이스 서버 설치의 경우, Oracle은 보안 향상을 위해 Oracle 홈 사용자로 (Windows 내장 계정 대신) 표준 Windows 사용자 계정을 사용할 것을 권장합니다.
다양한 유형의 Windows 계정에 대한 자세한 내용은 Microsoft 설명서를 참조하십시오
예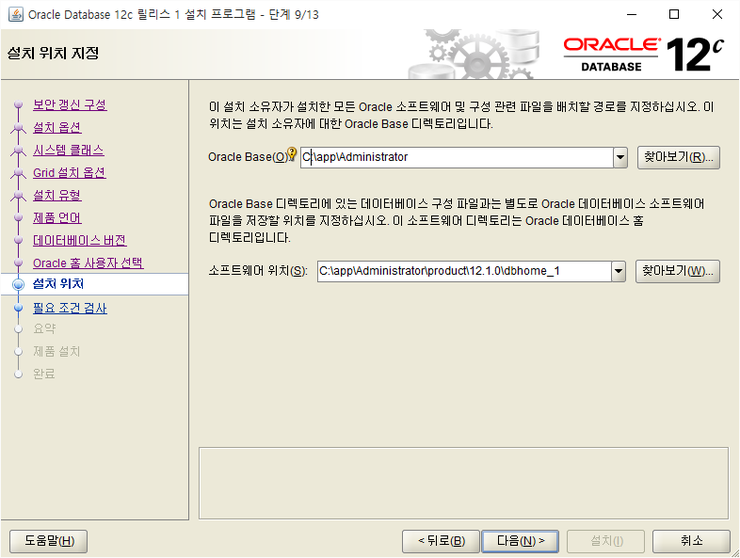
기본적 위치는 권한때문에 D로 잡힐것이다.
D로 설치해도 무난하다.
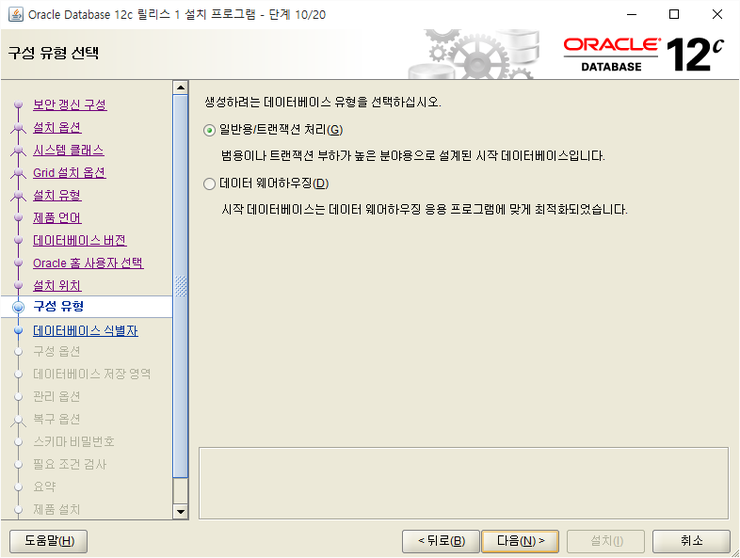
일반용/트랜잭션 처리
다음
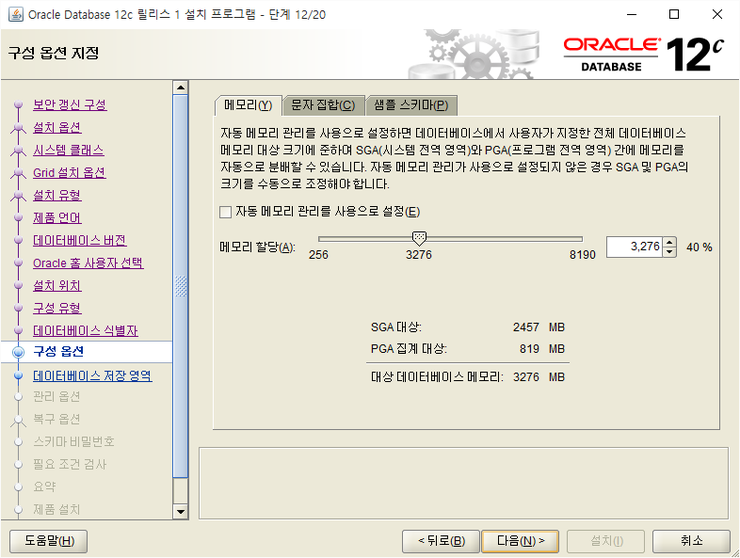
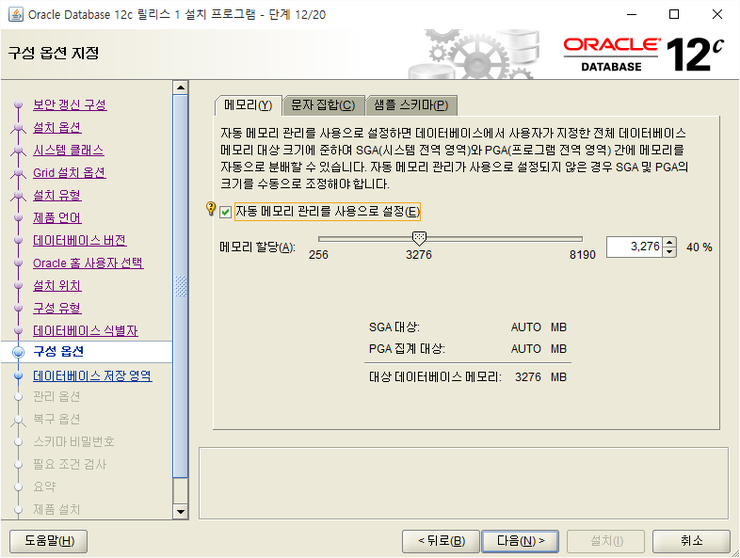
자동메모리 관리를 사용으로 설정 해도 상관없음
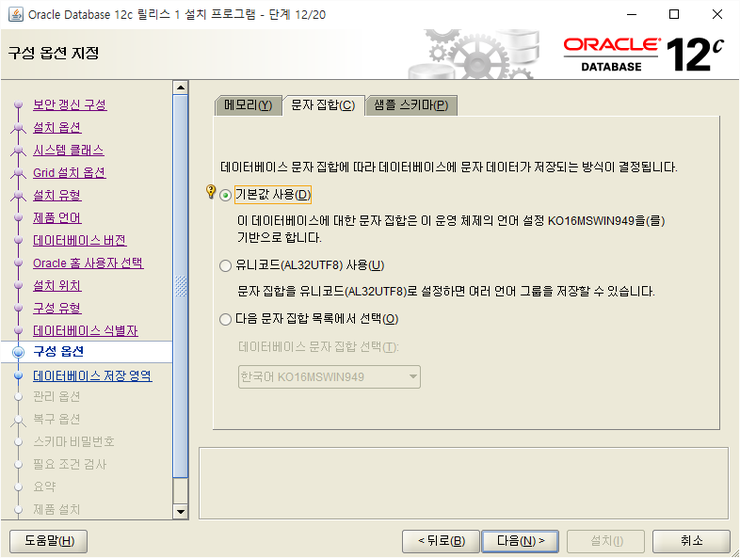
문자집합은 기본값 사용
다음
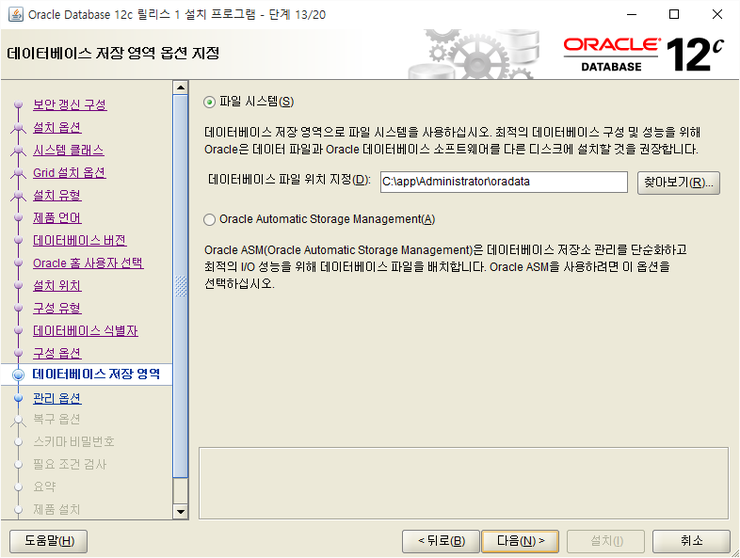
다음
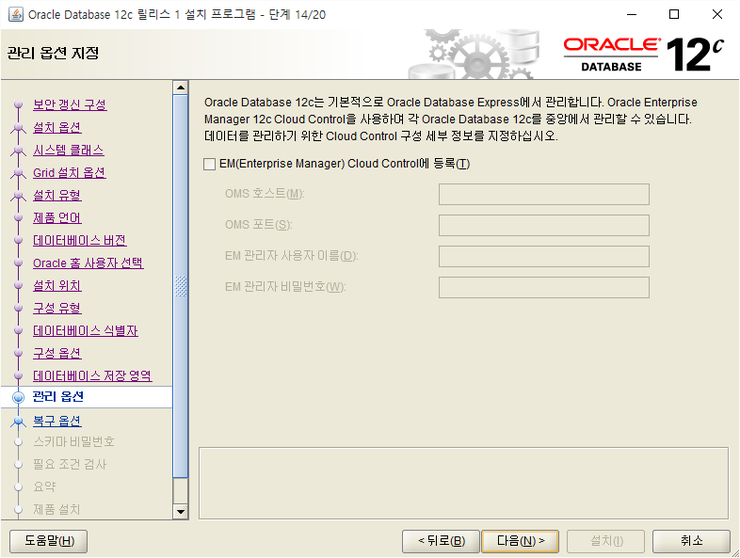
다음
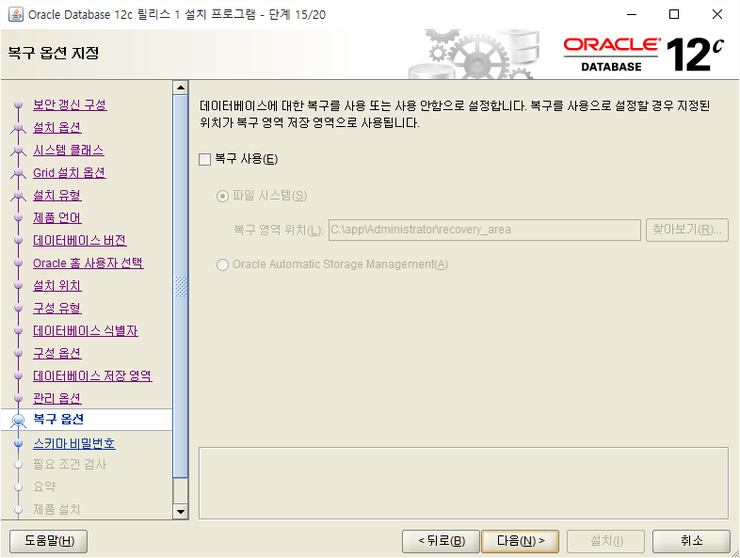
다음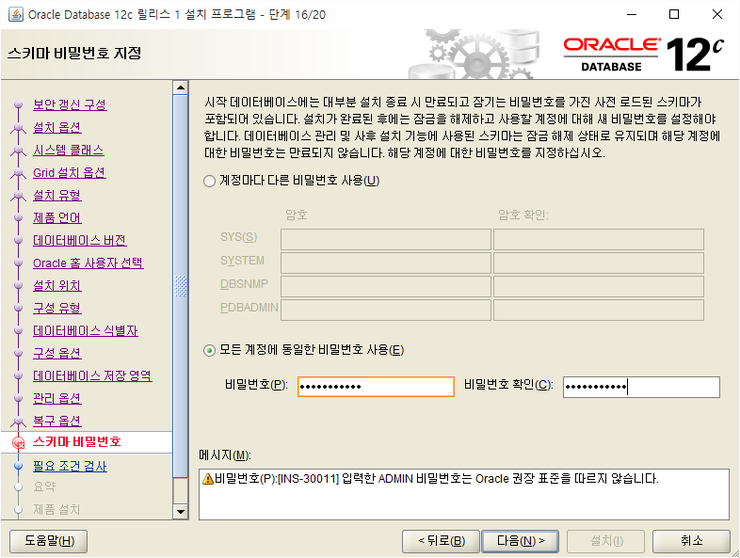
모든 계정에 동일한 비빌먼호 사용
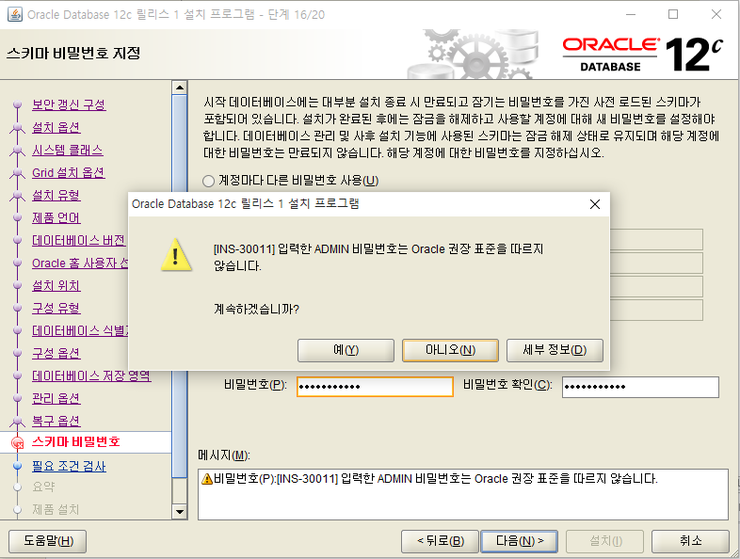
예
설치
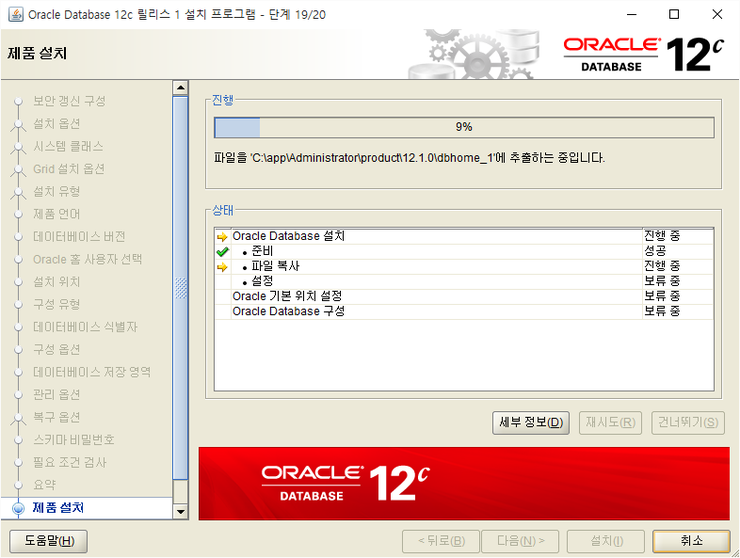
설치 도중 에러가 발생할수있다.
파일이 없다고 나올경우
winx64_12102_database_2of2 에있는
winx64_12102_database_2of2\database\stage 아래에있는 파일을 복사해서
winx64_12102_database_1of2\database\stage\Components 에 넣어주자
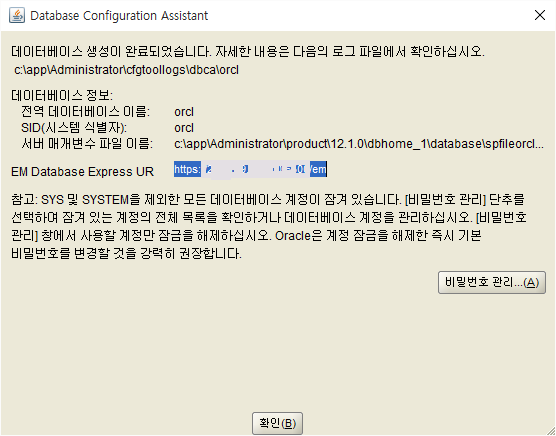
확인
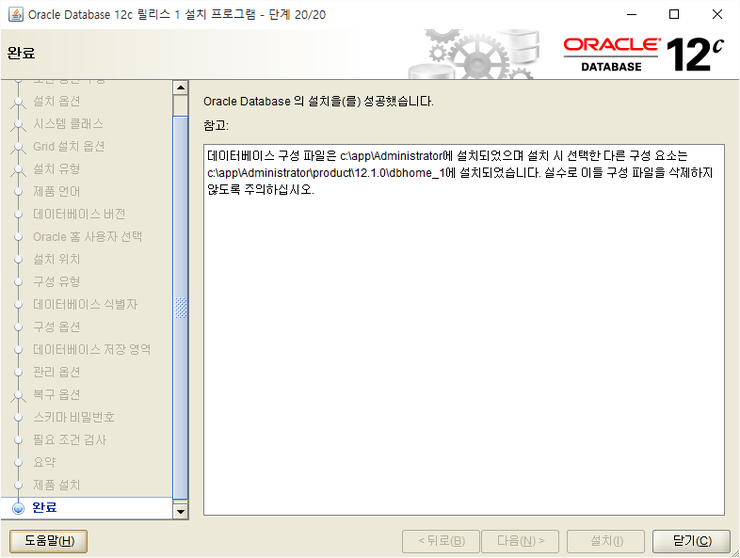
닫기
설치완료
이제부터 가장 중요한 확인 순서
cmd 창을 관리자 권한으로 접속
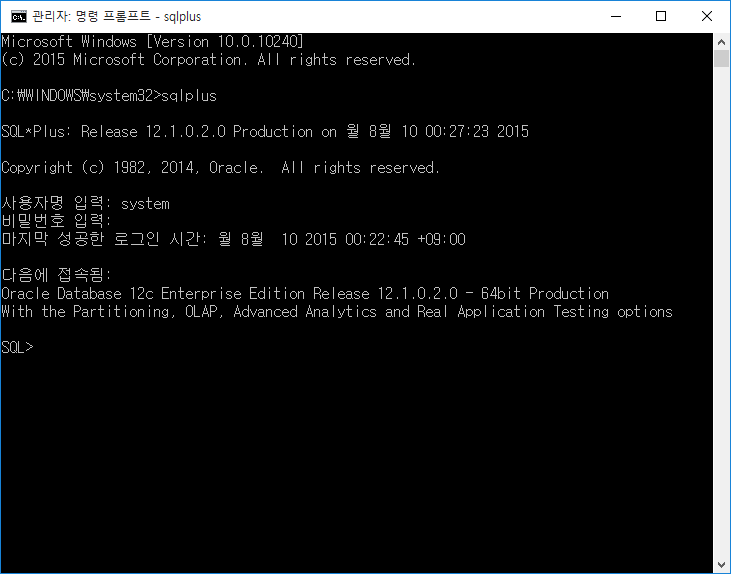
대소문자 구분 없애기
alter system set sec_case_sensitive_logon=false;
listenr.ora설정
|
listener.ora |
|
# listener.ora Network Configuration File: D:\app\Administrator\product\12.1.0\dbhome_1\network\admin\listener.ora SID_LIST_LISTENER = LISTENER = |
설치도중 ora-28547를 만날수 있다.
리스너에 HOST를 자신의 PC이름으로 변경하자
위치 : 제어판\시스템 및 보안\시스템
컴퓨터 이름: DESKTOP-XXXX
|
tnsnames.ora |
|
# tnsnames.ora Network Configuration File: c:\oracle\product\10.2.0\client\network\admin\tnsnames.ora EXTPROC_CONNECTION_DATA = ORCL = |
ORACLE SQL DEBELOPER
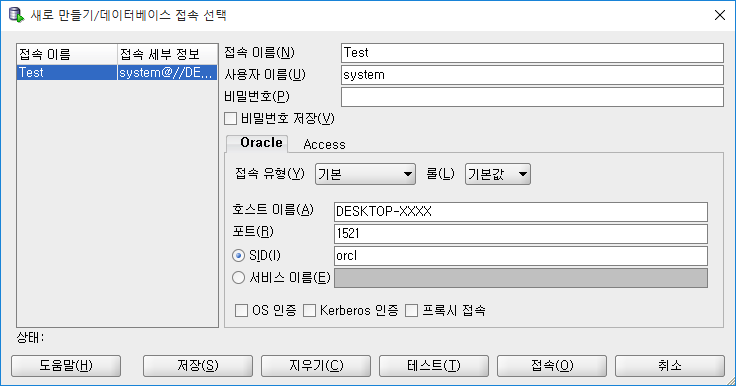
테스트 접속 성공
[출처] 윈도우10 Oracle12c R2 설치 (최신판 수정) |작성자 Hellojjong
'프로그램 > ORACLE' 카테고리의 다른 글
| 오라클 12c 계정만들기 (0) | 2016.12.16 |
|---|---|
| TNS 리스너가 없습니다. (0) | 2016.12.16 |
| 오라클 sysdba접속 방법 (0) | 2016.12.16 |
| [오라클] WM_CONCAT 함수 사용하기 (0) | 2016.11.30 |
| [오라클] TRIGGER 구문 정리 (0) | 2016.11.30 |








